TL;DR
1. kubernetes Scheduler 简介
kubernetes Scheduler 运行在 master 节点,它的核心功能是监听 apiserver 来获取 PodSpec.NodeName 为空的 pod,然后为每个这样的 pod 创建一个 binding 指示 pod 应该调度到哪个节点上。
从哪里读取还没有调度的 pod 呢?当然是 apiserver。怎么知道 pod 没有调度呢?我们在 介绍 APIServer 的文章讲到,可以通过 spec.nodeName 指定 pod 要部署在特定的节点上。调度器也是一样,它会向 apiserver 请求 spec.nodeName 字段为空的 pod,然后调度得到结果之后,把结果写入 apiserver。
虽然调度的原理说起来很简单,但是要编写一个优秀的调度器却不容易,因为要考虑的东西很多:
- 尽可能地将 workload 平均到不同的节点,减少单个节点宕机造成的损失
- 可扩展性。随着集群规模的增加,怎么保证调度器不会成为性能的瓶颈
- 高可用。调度器能做组成集群,任何一个调度器出现问题,不会影响整个集群的调度
- 灵活性。不同的用户有不同的调度需求,一个优秀的调度器还要允许用户能配置不同的调度算法
- 资源合理和高效利用。调度器应该尽可能地提高集群的资源利用率,防止资源的浪费
文章的最后,我们来分析一下 kubernetes 的调度器是否能做到这几点。
之前 kubernetes 调度简介的文章,我们介绍了调度分为两个过程:predicate 和 priority。这篇文章就继续深入到源码层面来解析 kubernetes 调度的过程。
和其他组件不同,scheduler 的代码在 plugin/ 目录下:plugin/cmd/kube-scheduler/ 是代码的 main 函数入口,plugin/pkg/scheduler/ 是具体调度算法。从这个目录结构也可以看出来,kube-scheduler 是作为插件接入到集群中的,它的最终形态一定是用户可以很容易地去定制化和二次开发的。
2. 代码分析
2.1 启动流程
虽然放到了 plugin/ 目录下,kube-scheduler 的启动过程和其他组件还是一样的,它会新建一个 SchedulerServer,这是一个保存了 scheduler 启动所需要配置信息的结构体,然后解析命令行的参数,对结构体中的内容进行赋值,最后运行 app.Run(s) 把 scheduler 跑起来。
plugin/cmd/kube-scheduler/scheduler.go:
func main() {
s := options.NewSchedulerServer()
s.AddFlags(pflag.CommandLine)
flag.InitFlags()
logs.InitLogs()
defer logs.FlushLogs()
verflag.PrintAndExitIfRequested()
app.Run(s)
}
app.Runs(s) 根据配置信息构建出来各种实例,然后运行 scheduler 的核心逻辑,这个函数会一直运行,不会退出。
plugin/cmd/kube-scheduler/app/server.go:
func Run(s *options.SchedulerServer) error {
......
configFactory := factory.NewConfigFactory(leaderElectionClient, s.SchedulerName, s.HardPodAffinitySymmetricWeight, s.FailureDomains)
config, err := createConfig(s, configFactory)
......
sched := scheduler.New(config)
run := func(_ <-chan struct{}) {
sched.Run()
select {}
}
......
// 多个 kube-scheduler 部署高可用集群会用到 leader election 功能
......
}
Run 方法的主要逻辑是这样的:根据传递过来的参数创建 scheduler 需要的配置(主要是需要的各种结构体),然后调用 scheduler 的接口创建一个新的 scheduler 对象,最后运行这个对象开启调度代码。需要注意的是,config 这个对象也是在 configFactory 的基础上创建出来的。
了解 config 的创建和内容对后面了解调度器的工作原理非常重要,所以我们先来分下它的代码。
2.2 Config 的创建
factory.NewConfigFactory 方法会创建一个 ConfigFactory 的对象,这个对象里面主要是一些 ListAndWatch,用来从 apiserver 中同步各种资源的内容,用作调度时候的参考。此外,还有两个特别重要的结构体成员:PodQueue 和 PodLister,PodQueue 队列中保存了还没有调度的 pod,PodLister 同步未调度的 Pod 和 Pod 的状态信息。
plugin/pkg/scheduler/factory/factory.go:
func NewConfigFactory(client clientset.Interface, schedulerName string, hardPodAffinitySymmetricWeight int, failureDomains string) *ConfigFactory {
// schedulerCache 保存了 pod 和 node 的信息,是调度过程中两者信息的 source of truth
schedulerCache := schedulercache.New(30*time.Second, stopEverything)
informerFactory := informers.NewSharedInformerFactory(client, 0)
pvcInformer := informerFactory.PersistentVolumeClaims()
c := &ConfigFactory{
Client: client,
PodQueue: cache.NewFIFO(cache.MetaNamespaceKeyFunc),
ScheduledPodLister: &cache.StoreToPodLister{},
informerFactory: informerFactory,
// ConfigFactory 中非常重要的一部分就是各种 `Lister`,用来从获取各种资源列表,它们会和 apiserver 保持实时同步
NodeLister: &cache.StoreToNodeLister{},
PVLister: &cache.StoreToPVFetcher{Store: cache.NewStore(cache.MetaNamespaceKeyFunc)},
PVCLister: pvcInformer.Lister(),
pvcPopulator: pvcInformer.Informer().GetController(),
ServiceLister: &cache.StoreToServiceLister{Indexer: cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})},
ControllerLister: &cache.StoreToReplicationControllerLister{Indexer: cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})},
ReplicaSetLister: &cache.StoreToReplicaSetLister{Indexer: cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})},
schedulerCache: schedulerCache,
StopEverything: stopEverything,
SchedulerName: schedulerName,
HardPodAffinitySymmetricWeight: hardPodAffinitySymmetricWeight,
FailureDomains: failureDomains,
}
// PodLister 和其他 Lister 创建方式不同,它就是 `schedulerCache`
c.PodLister = schedulerCache
// ScheduledPodLister 保存了已经调度的 pod, 即 `Spec.NodeName` 不为空且状态不是 Failed 或者 Succeeded 的 pod
// Informer 是对 reflector 的一层封装,reflect 把 ListWatcher 的结果实时更新到 store 中,而 informer 在每次更新的时候会调用对应的 handler 函数。
// 这里的 handler 函数把 store 中的 pod 数据更新到 schedulerCache 中
c.ScheduledPodLister.Indexer, c.scheduledPodPopulator = cache.NewIndexerInformer(
c.createAssignedNonTerminatedPodLW(),
&api.Pod{},
0,
cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToCache,
UpdateFunc: c.updatePodInCache,
DeleteFunc: c.deletePodFromCache,
},
cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc},
)
// 同上,把 node 的数据实时同步到 schedulerCache
c.NodeLister.Store, c.nodePopulator = cache.NewInformer(
c.createNodeLW(),
&api.Node{},
0,
cache.ResourceEventHandlerFuncs{
AddFunc: c.addNodeToCache,
UpdateFunc: c.updateNodeInCache,
DeleteFunc: c.deleteNodeFromCache,
},
)
......
return c
}
ConfigFactory 里面保存了各种 Lister,它们用来获取 kubernetes 中各种资源的信息,并且 schedulerCache 中保存了调度过程中需要用到的 pods 和 nodes 的最新信息。
然后,createConfig(s, configFactory) 根据配置参数和 configFactory 创建出真正被 scheduler 使用的 config 对象。
func createConfig(s *options.SchedulerServer, configFactory *factory.ConfigFactory) (*scheduler.Config, error) {
if _, err := os.Stat(s.PolicyConfigFile); err == nil {
var (
policy schedulerapi.Policy
configData []byte
)
configData, err := ioutil.ReadFile(s.PolicyConfigFile)
......
if err := runtime.DecodeInto(latestschedulerapi.Codec, configData, &policy); err != nil {
return nil, fmt.Errorf("invalid configuration: %v", err)
}
return configFactory.CreateFromConfig(policy)
}
return configFactory.CreateFromProvider(s.AlgorithmProvider)
}
createConfig 根据不同的配置有两种方式来创建 scheduler.Config:
- 通过 policy 文件:用户编写调度器用到的 policy 文件,控制调度器使用哪些 predicates 和 priorities 函数
- 通过 algorithm provider:已经在代码中提前编写好的 provider,也就是 predicates 和 priorities 函数的组合
这两种方法殊途同归,最终都是获取到 predicates 和 priorities 的名字,然后调用 CreateFromKeys 创建 Config 对象:
func (f *ConfigFactory) CreateFromKeys(predicateKeys, priorityKeys sets.String, extenders []algorithm.SchedulerExtender) (*scheduler.Config, error) {
// 获取所有的 predicates 函数
predicateFuncs, err := f.GetPredicates(predicateKeys)
// priority 返回的不是函数,而是 priorityConfigs。一是因为 priority 还包含了权重,二是因为 priority 的实现在迁移到 map-reduce 的方式
priorityConfigs, err := f.GetPriorityFunctionConfigs(priorityKeys)
// 两种 MetaProducer 都是用来获取调度中用到的 metadata 信息,比如 affinity、toleration,pod ports(用到的端口)、resource request(请求的资源)等
priorityMetaProducer, err := f.GetPriorityMetadataProducer()
predicateMetaProducer, err := f.GetPredicateMetadataProducer()
// 运行各种 informer 的内部逻辑,从 apiserver 同步资源数据到 Lister 和 cache 中
f.Run()
// 构造出 schedulerAlgorithm 对象,它最核心的方法是 `Schedule` 方法,我们会在下文说到
algo := scheduler.NewGenericScheduler(f.schedulerCache, predicateFuncs, predicateMetaProducer, priorityConfigs, priorityMetaProducer, extenders)
......
// 返回最终的 Config 对象
return &scheduler.Config{
SchedulerCache: f.schedulerCache,
NodeLister: f.NodeLister.NodeCondition(getNodeConditionPredicate()),
Algorithm: algo,
Binder: &binder{f.Client},
PodConditionUpdater: &podConditionUpdater{f.Client},
// NextPod 就是从 PodQueue 中取出 下一个未调度的 pod
NextPod: func() *api.Pod {
return f.getNextPod()
},
// 调度出错时的处理函数,会把 pod 重新加入到 podQueue 中,等待下一次调度
Error: f.makeDefaultErrorFunc(&podBackoff, f.PodQueue),
StopEverything: f.StopEverything,
}, nil
}
Config 的定义在文件 plugins/pkg/scheduler/scheduler.go 中。它把调度器的逻辑分成几个组件,提供了这些功能:
NextPod()方法能返回下一个需要调度的 podAlgorithm.Schedule()方法能计算出某个 pod 在节点中的结果Error()方法能够在出错的时候重新把 pod 放到调度队列中进行重试schedulerCache能够暂时保存调度中的 pod 信息,占用着 pod 需要的资源,保证资源不会冲突Binder.Bind在调度成功之后把调度结果发送到 apiserver 中保存起来
后面可以看到 Scheduler 对象就是组合这些逻辑组件来完成最终的调度任务的。
Config 中的逻辑组件中,负责调度 pod 的是 Algorithm.Schedule() 方法。其对应的值是 GenericScheduler,GenericScheduler 是 Scheduler 的一种实现,也是 kube-scheduler 默认使用的调度器,它只负责单个 pod 的调度并返回结果:
plugin/pkg/scheduler/generic_scheduler.go
func NewGenericScheduler(
cache schedulercache.Cache,
predicates map[string]algorithm.FitPredicate,
predicateMetaProducer algorithm.MetadataProducer,
prioritizers []algorithm.PriorityConfig,
priorityMetaProducer algorithm.MetadataProducer,
extenders []algorithm.SchedulerExtender) algorithm.ScheduleAlgorithm {
return &genericScheduler{
cache: cache,
predicates: predicates,
predicateMetaProducer: predicateMetaProducer,
prioritizers: prioritizers,
priorityMetaProducer: priorityMetaProducer,
extenders: extenders,
cachedNodeInfoMap: make(map[string]*schedulercache.NodeInfo),
}
}
调度算法的接口只有一个方法:Schedule,第一个参数是要调度的 pod,第二个参数是能够获取 node 列表的接口对象。它返回一个节点的名字,表示 pod 将会调度到这台节点上。
plugin/pkg/scheduler/algorithm/scheduler_interface.go
type ScheduleAlgorithm interface {
Schedule(*api.Pod, NodeLister) (selectedMachine string, err error)
}
Config 创建出来之后,就是 scheduler 的创建和运行,执行最核心的调度逻辑,不断为所有需要调度的 pod 选择合适的节点:
sched := scheduler.New(config)
run := func(_ <-chan struct{}) {
sched.Run()
select {}
}
总结起来,configFactory、config 和 scheduler 三者的关系如下图所示:
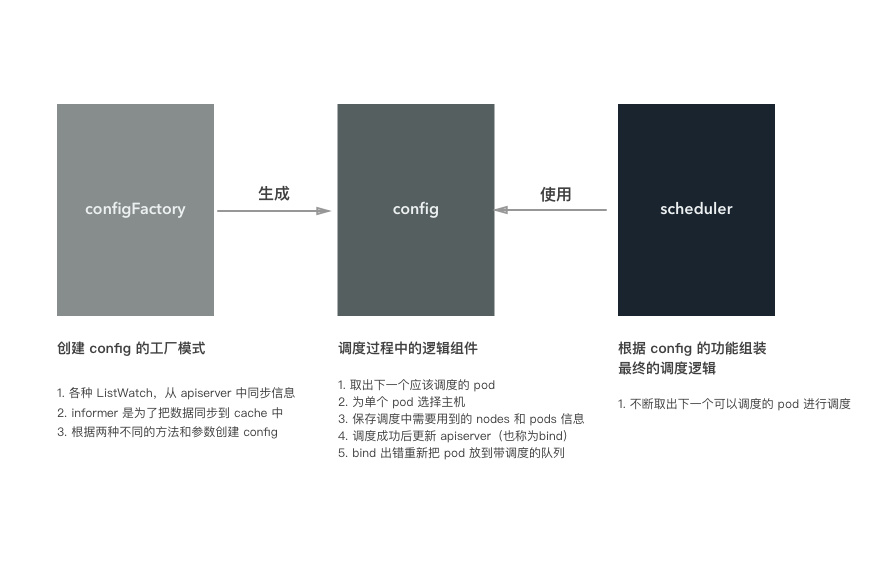
configFactory对应工厂模式的工厂模型,根据不同的配置和参数生成config,当然事先会准备好config需要的各种数据config是调度器中最重要的组件,里面实现了调度的各个组件逻辑scheduler使用config提供的功能来完成调度
如果把调度对比成做菜,那么构建 config 就相当于准备食材和调料、洗菜、对食材进行预处理。做菜就是把准备的食材变成美味佳肴的过程!
2.3 调度的逻辑
接着上面分析,看看 scheduler 创建和运行的过程。其对应的代码在 plugin/pkg/scheduler/scheduler.go 文件中:
// Scheduler 结构体本身非常简单,它把所有的东西都放到了 `Config` 对象中
type Scheduler struct {
config *Config
}
// 创建 scheduler 就是把 config 放到结构体中
func New(c *Config) *Scheduler {
s := &Scheduler{
config: c,
}
return s
}
func (s *Scheduler) Run() {
go wait.Until(s.scheduleOne, 0, s.config.StopEverything)
}
func (s *Scheduler) scheduleOne() {
pod := s.config.NextPod()
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
......
// assumed 表示已经为 pod 选择了 host,但是还没有在 apiserver 中创建绑定
// 这个状态的 pod 会单独保存在 schedulerCache 中,并暂时占住了节点上的资源
assumed := *pod
assumed.Spec.NodeName = dest
if err := s.config.SchedulerCache.AssumePod(&assumed); err != nil {
return
}
// 异步对 pod 进行 bind 操作
go func() {
b := &api.Binding{
ObjectMeta: api.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name},
Target: api.ObjectReference{
Kind: "Node",
Name: dest,
},
}
err := s.config.Binder.Bind(b)
if err != nil {
// 绑定失败,删除 pod 的信息,占用的节点资源也被释放,可以让其他 pod 使用
if err := s.config.SchedulerCache.ForgetPod(&assumed); err != nil {
glog.Errorf("scheduler cache ForgetPod failed: %v", err)
}
s.config.PodConditionUpdater.Update(pod, &api.PodCondition{
Type: api.PodScheduled,
Status: api.ConditionFalse,
Reason: "BindingRejected",
})
return
}
}()
}
scheduler.Run 就是不断调用 scheduler.scheduleOne() 每次调度一个 pod。
对应的调度逻辑如下图所示:

接下来我们逐步分解和解释。
2.3.1 下一个需要调度的 pod
NextPod 函数就是 configFactory.getNextPod(),它从未调度的队列中返回下一个应该由当前调度器调度的 pod。
它从 configFactory.PodQueue 中 pop 出来一个应该由当前调度器调度的 pod。当前 pod 可以通过 scheduler.alpha.kubernetes.io/name annotation 来设置调度器的名字,如果调度器名字发现这个名字和自己一致就认为 pod 应该由自己调度。如果对应的值为空,则默认调度器会进行调度。
PodQueue 是一个先进先出的队列: PodQueue: cache.NewFIFO(cache.MetaNamespaceKeyFunc),这个 FIFO 的实现代码在 pkg/client/cache/fifo.go 文件中。PodQueue 的内容是 reflector 从 apiserver 实时同步过来的,里面保存了需要调度的 pod(spec.nodeName 为空,而且状态不是 success 或者 failed):
func (f *ConfigFactory) Run() {
// Watch and queue pods that need scheduling.
cache.NewReflector(f.createUnassignedNonTerminatedPodLW(), &api.Pod{}, f.PodQueue, 0).RunUntil(f.StopEverything)
......
}
func (factory *ConfigFactory) createUnassignedNonTerminatedPodLW() *cache.ListWatch {
selector := fields.ParseSelectorOrDie("spec.nodeName==" + "" + ",status.phase!=" + string(api.PodSucceeded) + ",status.phase!=" + string(api.PodFailed))
return cache.NewListWatchFromClient(factory.Client.Core().RESTClient(), "pods", api.NamespaceAll, selector)
}
2.3.2 调度单个 pod
拿到 pod 之后,就调用具体的调度算法选择一个节点。
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
上面已经讲过,默认的调度算法就是 generic_scheduler,它的代码在 plugin/pkg/scheduler/generic_scheduler.go 文件:
func (g *genericScheduler) Schedule(pod *api.Pod, nodeLister algorithm.NodeLister) (string, error) {
// 第一步:从 nodeLister 中获取 node 的信息
nodes, err := nodeLister.List()
......
// schedulerCache 中保存了调度用到的 pod 和 node 的最新数据,用里面的数据更新 `cachedNodeInfoMap`,作为调度过程中节点信息的参考
err = g.cache.UpdateNodeNameToInfoMap(g.cachedNodeInfoMap)
// 第二步:执行 predicate,过滤符合调度条件的节点
filteredNodes, failedPredicateMap, err := findNodesThatFit(pod, g.cachedNodeInfoMap, nodes, g.predicates, g.extenders, g.predicateMetaProducer)
if len(filteredNodes) == 0 {
return "", &FitError{
Pod: pod,
FailedPredicates: failedPredicateMap,
}
}
// 第三步:执行 priority,为符合条件的节点排列优先级
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.cachedNodeInfoMap)
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return "", err
}
// 第四步:从最终的结果中选择一个节点
return g.selectHost(priorityList)
}
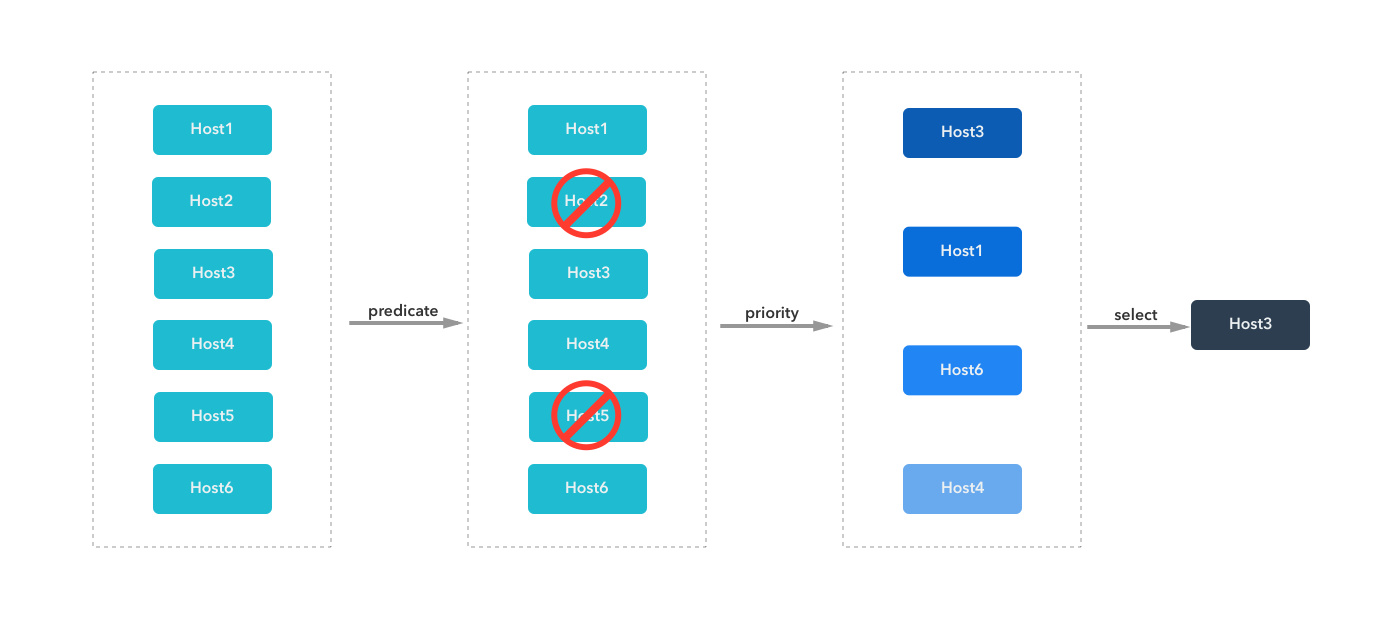
调度算法的过程分为四步骤:
- 获取必要的数据,这个当然就是 pod 和 nodes 信息。pod 是作为参数传递过来的,nodes 有两类,一个是通过
nodeLister获取的节点信息,一类是cachedNodeInfoMap。后一类节点信息中额外保存了资源的使用情况,比如节点上有多少调度的 pod、已经申请的资源、还可以分配的资源等 - 执行过滤操作。根据当前 pod 和 nodes 信息,过滤掉不适合运行 pod 的节点
- 执行优先级排序操作。对适合 pod 运行的节点进行优先级排序
- 选择节点。从最终优先级最高的节点中选择出来一个作为 pod 调度的结果
下面的几个部分就来讲讲过滤和优先级排序的过程。
2.3.3 过滤(Predicate):移除不合适的节点
调度器的输入是一个 pod(多个 pod 调度可以通过遍历来实现) 和多个节点,输出是一个节点,表示 pod 将被调度到这个节点上。
如何找到最合适 pod 运行的节点呢?第一步就是移除不符合调度条件的节点,这个过程 kubernetes 称为 Predicate,这个单词在这里怎么翻译成中文我也不是很确定,韦氏词典给出了这样的定义:
something that is affirmed or denied of the subject in a proposition in logic.
- merriam webster
这个过程用 filter 对我来说会更直观,容易理解,所以下面我们都将这一过程称作过滤。
过滤调用的函数是 findNodesThatFit,代码在 plugins/pkg/scheduler/generic_scheduler.go 文件中:
func findNodesThatFit(
pod *api.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
nodes []*api.Node,
predicateFuncs map[string]algorithm.FitPredicate,
extenders []algorithm.SchedulerExtender,
metadataProducer algorithm.MetadataProducer,
) ([]*api.Node, FailedPredicateMap, error) {
// filtered 保存通过过滤的节点
var filtered []*api.Node
// failedPredicateMap 保存过滤失败的节点,即不适合 pod 运行的节点
failedPredicateMap := FailedPredicateMap{}
if len(predicateFuncs) == 0 {
filtered = nodes
} else {
filtered = make([]*api.Node, len(nodes))
errs := []error{}
var predicateResultLock sync.Mutex
var filteredLen int32
// meta 函数可以查询 pod 和 node 的信息
meta := metadataProducer(pod, nodeNameToInfo)
// 检查单个 node 能否运行某个 pod
checkNode := func(i int) {
nodeName := nodes[i].Name
fits, failedPredicates, err := podFitsOnNode(pod, meta, nodeNameToInfo[nodeName], predicateFuncs)
......
if fits {
filtered[atomic.AddInt32(&filteredLen, 1)-1] = nodes[i]
} else {
predicateResultLock.Lock()
failedPredicateMap[nodeName] = failedPredicates
predicateResultLock.Unlock()
}
}
// 使用 workQueue 来并行运行检查,并发数最大是 16
workqueue.Parallelize(16, len(nodes), checkNode)
filtered = filtered[:filteredLen]
if len(errs) > 0 {
return []*api.Node{}, FailedPredicateMap{}, errors.NewAggregate(errs)
}
}
// 在基本过滤的基础上,继续执行 extender 的过滤逻辑
.....
return filtered, failedPredicateMap, nil
}
上面这段代码主要的工作是对 pod 过滤工作进行并发控制、错误处理和结果保存。没有通过过滤的节点信息保存在 failedPredicateMap 字典中,key 是节点名,value 是失败原因的列表;通过过滤的节点保存在 filtered 数组中。
对于每个 pod,都要检查能否调度到集群中的所有节点上(只包括可调度的节点),而且多个判断逻辑之间是独立的,也就是说 pod 是否能否调度到某个 node 上和其他 node 无关(至少目前是这样的,如果这个假设不再成立,并发要考虑协调的问题),所以可以使用并发来提高性能。并发是通过 workQueue 来实现的,最大并发数量是 16,这个数字是 hard code。
pod 和 node 是否匹配是调用是 podFitsOnNode 函数来判断的:
func podFitsOnNode(pod *api.Pod, meta interface{}, info *schedulercache.NodeInfo, predicateFuncs map[string]algorithm.FitPredicate) (bool, []algorithm.PredicateFailureReason, error) {
var failedPredicates []algorithm.PredicateFailureReason
for _, predicate := range predicateFuncs {
fit, reasons, err := predicate(pod, meta, info)
if err != nil {
err := fmt.Errorf("SchedulerPredicates failed due to %v, which is unexpected.", err)
return false, []algorithm.PredicateFailureReason{}, err
}
if !fit {
failedPredicates = append(failedPredicates, reasons...)
}
}
return len(failedPredicates) == 0, failedPredicates, nil
}
它会循环调用所有的 predicateFuncs 定义的过滤方法,并返回节点是否满足调度条件,以及可能的错误信息。每个 predicate 函数的类型是这样的:
plugin/pkg/scheduler/algorithm/types.go
type FitPredicate func(pod *api.Pod, meta interface{}, nodeInfo *schedulercache.NodeInfo) (bool, []PredicateFailureReason, error)
它接受三个参数:
- pod:要调度的 pod
- meta:获取过滤过程中 pod 以及调度参数的函数
- nodeInfo:要过滤的 node 信息
具体的 predicate 实现都在 plugin/pkg/scheduler/algorithm/predicates/predicates.go:
NoVolumeZoneConflict:pod 请求的 volume 是否能在节点所在的 Zone 使用。通过匹配 node 和 PV 的failure-domain.beta.kubernetes.io/zone和failure-domain.beta.kubernetes.io/region来决定MaxEBSVolumeCount:请求的 volumes 是否超过 EBS(Elastic Block Store) 支持的最大值,默认是 39MaxGCEPDVolumeCount:请求的 volumes 是否超过 GCE 支持的最大值,默认是 16MatchInterPodAffinity:根据 inter-pod affinity 来决定 pod 是否能调度到节点上。这个过滤方法会看 pod 是否和当前节点的某个 pod 互斥。关于亲和性和互斥性,可以查看之前的文章。NoDiskConflict:检查 pod 请求的 volume 是否就绪和冲突。如果主机上已经挂载了某个卷,则使用相同卷的 pod 不能调度到这个主机上。kubernetes 使用的 volume 类型不同,过滤逻辑也不同。比如不同云主机的 volume 使用限制不同:GCE 允许多个 pods 使用同时使用 volume,前提是它们是只读的;AWS 不允许 pods 使用同一个 volume;Ceph RBD 不允许 pods 共享同一个 monitorGeneralPredicates:普通过滤函数,主要考虑 kubernetes 资源是否能够满足,比如 CPU 和 Memory 是否足够,端口是否冲突、selector 是否匹配PodFitsResources:检查主机上的资源是否满足 pod 的需求。资源的计算是根据主机上运行 pod 请求的资源作为参考的,而不是以实际运行的资源数量PodFitsHost:如果 pod 指定了spec.NodeName,看节点的名字是否何它匹配,只有匹配的节点才能运行 podPodFitsHostPorts:检查 pod 申请的主机端口是否已经被其他 pod 占用,如果是,则不能调度PodSelectorMatches:检查主机的标签是否满足 pod 的 selector。包括 NodeAffinity 和 nodeSelector 中定义的标签。
PodToleratesNodeTaints:根据 taints 和 toleration 的关系判断 pod 是否可以调度到节点上CheckNodeMemoryPressure:检查 pod 能否调度到内存有压力的节点上。如有节点有内存压力, guaranteed pod(request 和 limit 相同) 不能调度到节点上。相关资料请查看 Resource QoS DesignCheckNodeDiskPressure:检查 pod 能否调度到磁盘有压力的节点上,目前所有的 pod 都不能调度到磁盘有压力的节点上
每个过滤函数的逻辑都不复杂,只需要了解相关的概念就能读懂。这篇文章只讲解 PodFitsResources 的实现,也就是判断节点上的资源是否能满足 pod 的请求。
plugin/pkg/scheduler/algorithm/predicates/predicates.go:
func PodFitsResources(pod *api.Pod, meta interface{}, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
node := nodeInfo.Node()
var predicateFails []algorithm.PredicateFailureReason
// 判断节点上 pod 数量是否超过限制
allowedPodNumber := nodeInfo.AllowedPodNumber()
if len(nodeInfo.Pods())+1 > allowedPodNumber {
predicateFails = append(predicateFails, NewInsufficientResourceError(api.ResourcePods, 1, int64(len(nodeInfo.Pods())), int64(allowedPodNumber)))
}
// 获取 pod 请求的资源,目前支持 CPU、Memory 和 GPU
var podRequest *schedulercache.Resource
if predicateMeta, ok := meta.(*predicateMetadata); ok {
podRequest = predicateMeta.podRequest
} else {
podRequest = GetResourceRequest(pod)
}
......
// 判断如果 pod 放到节点上,是否超过节点可分配的资源
allocatable := nodeInfo.AllocatableResource()
if allocatable.MilliCPU < podRequest.MilliCPU+nodeInfo.RequestedResource().MilliCPU {
predicateFails = append(predicateFails, NewInsufficientResourceError(api.ResourceCPU, podRequest.MilliCPU, nodeInfo.RequestedResource().MilliCPU, allocatable.MilliCPU))
}
if allocatable.Memory < podRequest.Memory+nodeInfo.RequestedResource().Memory {
predicateFails = append(predicateFails, NewInsufficientResourceError(api.ResourceMemory, podRequest.Memory, nodeInfo.RequestedResource().Memory, allocatable.Memory))
}
if allocatable.NvidiaGPU < podRequest.NvidiaGPU+nodeInfo.RequestedResource().NvidiaGPU {
predicateFails = append(predicateFails, NewInsufficientResourceError(api.ResourceNvidiaGPU, podRequest.NvidiaGPU, nodeInfo.RequestedResource().NvidiaGPU, allocatable.NvidiaGPU))
}
for rName, rQuant := range podRequest.OpaqueIntResources {
if allocatable.OpaqueIntResources[rName] < rQuant+nodeInfo.RequestedResource().OpaqueIntResources[rName] {
predicateFails = append(predicateFails, NewInsufficientResourceError(rName, podRequest.OpaqueIntResources[rName], nodeInfo.RequestedResource().OpaqueIntResources[rName], allocatable.OpaqueIntResources[rName]))
}
}
......
return len(predicateFails) == 0, predicateFails, nil
}
有了前面准备的所有内容,判断节点资源是否满足就简单。只需要把 pod 请求的各种资源和节点上可用的资源比较大小。需要注意的是,如果 pod 没有添加要申请的资源,那么其对应的值为零,也就是说不会受到资源不足影响,同时也不会受资源限制。
节点上可分配资源是 kubelet 发送给 apiserver 的,而已经请求的资源数量是上面运行的 pods 资源的总和。主要的逻辑就是判断如果 pod 调度到节点上,那么所有 pods 请求的资源总和是否超过节点可用的资源数量,只要有任何一个资源超标,就认为无法调度到 node 上。
2.3.4 优先级(Priority):为合适的节点排序
过滤结束后,剩下的节点都是 pod 可以调度到上面的。如果过滤阶段就把所有的节点 pass 了,那么久直接返回调度错误;如果剩下多个节点,那么我们还要从这些可用的节点中选择一个。
虽然随机选择一个节点进行调度理论上也可以(毕竟它们都满足调度条件),但是我们还是希望能找到最合适的节点。什么是最合适呢?当然要根据需求来决定,但是有一些比较通用性的要求,比如 workload 在集群中要尽量均衡。不同的节点对 pod 的合适程度是不同的,优先级过程就是负责尽量找出更合适的节点的。
对每个节点,priority 函数都会计算出来一个 0-10 之间的数字,表示 pod 放到该节点的合适程度,其中 10 表示非常合适,0 表示非常不合适。每个不同的优先级函数都有一个权重值,这个值为正数,最终的值为权重和优先级函数结果的乘积,而一个节点的权重就是所有优先级函数结果的加和。比如有两种优先级函数 priorityFunc1 和 priorityFunc2,对应的权重分别为 weight1 和 weight2,那么节点 A 的最终得分是:
finalScoreNodeA = (weight1 * priorityFunc1) + (weight2 * priorityFunc2)
而权重最高的节点自然就是最合适的调度结果,优先级步骤对应函数 PrioritizeNodes:
func PrioritizeNodes(
pod *api.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
meta interface{},
priorityConfigs []algorithm.PriorityConfig,
nodes []*api.Node,
extenders []algorithm.SchedulerExtender,
) (schedulerapi.HostPriorityList, error) {
// 如果没有配置 priority,那么所有节点权重相同,最后的结果类似于随机选择一个节点
......
var (
mu = sync.Mutex{}
wg = sync.WaitGroup{}
errs []error
)
// results 是个二维表格,保存着每个节点对应每个优先级函数的得分
results := make([]schedulerapi.HostPriorityList, 0, len(priorityConfigs))
// 原来的计算方法,通过 `priorityConfig.Function` 计算分值。
// 每次取出一个优先级函数,计算所有节点的值
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Function != nil {
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
results[index], err = config.Function(pod, nodeNameToInfo, nodes)
}(i, priorityConfig)
} else {
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
}
}
// 以后会使用的计算方式,通过 map-reduce 的方式来计算分值
processNode := func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
var err error
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
continue
}
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
}
}
// 并发去计算结果
workqueue.Parallelize(16, len(nodes), processNode)
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Reduce == nil {
continue
}
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
if err := config.Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
}(i, priorityConfig)
}
// 等待所有计算结束
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
// 计算分值的总和,得到最终的结果
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
......
return result, nil
}
要想获得所有节点最终的权重分值,就要先计算每个优先级函数对应该节点的分值,然后计算总和。因此不管过程如何,如果有 N 个节点,M 个优先级函数,一定会计算 M*N 个中间值,构成一个二维表格:
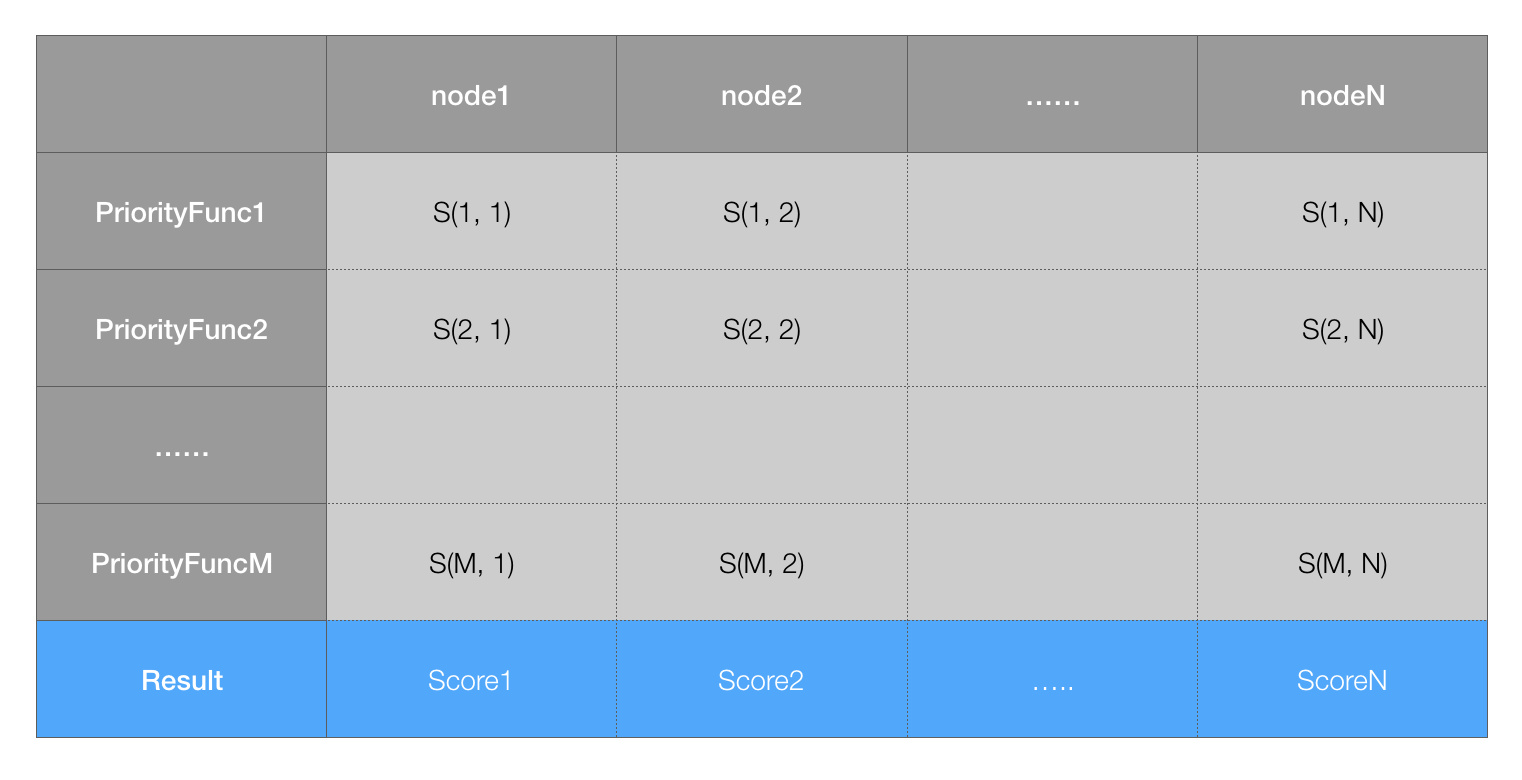
最后,会把表格中按照节点把优先级函数的权重列表相加,得到最终节点的分值。上面的代码就是这个过程,当然中间过程可以并发计算,以加快速度。
目前,kubernetes scheduler 提供了很多实用的优先级函数:
LeastRequestedPriority:最低请求优先级。根据 CPU 和内存的使用率来决定优先级,使用率越低优先级越高,也就是说优先调度到资源利用率低的节点,这个优先级函数能起到把负载尽量平均分到集群的节点上。默认权重为 1BalancedResourceAllocation:资源平衡分配。这个优先级函数会把 pod 分配到 CPU 和 memory 利用率差不多的节点(计算的时候会考虑当前 pod 一旦分配到节点的情况)。默认权重为 1SelectorSpreadPriority:尽量把同一个 service、replication controller、replica set 的 pod 分配到不同的节点,这些资源都是通过 selector 来选择 pod 的,所以名字才是这样的。默认权重为 1CalculateAntiAffinityPriority:尽量把同一个 service 下面某个 label 相同的 pod 分配到不同的节点ImageLocalityPriority:根据镜像是否已经存在的节点上来决定优先级,节点上存在要使用的镜像,而且镜像越大,优先级越高。这个函数会尽量把 pod 分配到下载镜像花销最少的节点NodeAffinityPriority:NodeAffinity,默认权重为 1InterPodAffinityPriority:根据 pod 之间的亲和性决定 node 的优先级,默认权重为 1NodePreferAvoidPodsPriority:默认权重是 10000,把这个权重设置的那么大,就以为这一旦该函数的结果不为 0,就由它决定排序结果TaintTolerationPriority:默认权重是 1
不同的优先级函数计算出来节点的权重值是个 [0-10] 的值,也就是它们本身就要做好规范化。如果认为某个优先级函数非常重要,那就增加它的 weight。
对于优先级函数,我们只讲解 LeastRequestedPriority 和 BalancedResourceAllocation 的实现,因为它们两个和资源密切相关。
最小资源请求优先级函数会计算每个节点的资源利用率,它目前只考虑 CPU 和内存两种资源,而且两者权重相同,具体的资源公式为:
score = (CPU Usage rate * 10 + Memory Usage Rate * 10 )/2
利用率的计算一样,都是 (capacity - requested)/capacity,capacity 指节点上资源的容量,比如 CPU 的核数,内存的大小;requested 表示节点当前所有 pod 请求对应资源的总和。
代码就不放出来了,就是做一个算术运算,对应的文件在:plugin/pkg/scheduler/algorithm/priorities/lease_requested.go。
平衡资源优先级函数会计算 CPU 和内存的平衡度,并尽量选择更均衡的节点。它会分别计算 CPU 和内存的,计算公式为:
10 - abs(cpuFraction - memoryFraction)*10
对应的 cpuFraction 和 memoryFraction 就是资源利用率,计算公式都是 requested/capacity。这种方法不推荐单独使用,一定要和最小资源请求一起使用。最小资源请求能尽量选择资源使用率低的节点,而这个方法会尽量考虑资源使用率比较平衡的节点。它能避免这样的情况:节点上 CPU 已经使用完了,剩下很多内存空间可用,但是因为 CPU 不再满足任何 pod 的请求,因此无法调度任何 pod,导致内存资源白白浪费。
这种实现主要参考了 an energy efficient virtual machine placement algorithm with balanced resource utilization 论文提出的方法,感兴趣的可以自行搜索阅读。
2.3.5 选择节点作为调度结果
优先级阶段不会移除任何的节点,只是对节点添加了一个分值,根据分值排序,分值最高的就是最终的结果。
如果分值最高的节点有多个,就“随机”选择一个。这个步骤就是 selectHost 的逻辑:
func (g *genericScheduler) selectHost(priorityList schedulerapi.HostPriorityList) (string, error) {
// 没有节点,直接返回错误
if len(priorityList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
// 根据权重分值从高到低排序
sort.Sort(sort.Reverse(priorityList))
// 找到所有最高分值的节点
maxScore := priorityList[0].Score
firstAfterMaxScore := sort.Search(len(priorityList), func(i int) bool { return priorityList[i].Score < maxScore })
// “随机”选择一个:其实是类似于 roundrobin 方法,记录一个 lastNodeIndex 不断加一,对可用节点数取模
g.lastNodeIndexLock.Lock()
ix := int(g.lastNodeIndex % uint64(firstAfterMaxScore))
g.lastNodeIndex++
g.lastNodeIndexLock.Unlock()
// 返回结果
return priorityList[ix].Host, nil
}
这个过程非常简单,没有需要过多解释的地方,代码关键步骤已经写上了注释。
3. 自定义调度器
如果对调度没有特殊的要求,使用 kube-schduler 的默认调度就能满足大部分的需求。如果默认调度不能满足需求,就要对调度进行自定义。这部分介绍几种用户可以自定义调度逻辑的方法!
3.1 修改 policy 文件
kube-scheduler 在启动的时候可以通过 --policy-config-file 参数可以指定调度策略文件,用户可以根据需要组装 predicates 和 priority 函数。选择不同的过滤函数和优先级函数、控制优先级函数的权重、调整过滤函数的顺序都会影响调度过程。
可以参考官方给出的 policy 文件实例:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "EqualPriority", "weight" : 1}
],
"hardPodAffinitySymmetricWeight" : 10
}
3.2 编写自己的 priority 和 predicate 函数
前一种方法就是对已有的调度模块(过滤函数和优先级函数)进行组合,如果有特殊的需求这些模块本身无法满足,用户还可以编写自己的过滤函数和优先级函数。
过滤函数的接口已经说过:
plugin/pkg/scheduler/algorithm/types.go
type FitPredicate func(pod *v1.Pod, meta interface{}, nodeInfo *schedulercache.NodeInfo) (bool, []PredicateFailureReason, error)
用户只需要在 plugin/pkg/scheduler/algorithm/predicates/predicates.go 文件中编写对象实现这个接口就行。
编写完过滤函数还要把它用起来,下一步就是把它进行注册,让 kube-scheduler 启动的时候知道它的存在,注册部分可以在 plugin/pkg/scheduler/algorithmprovider/defaults/defaults.go 完成,可以参考其他过滤函数的注册代码:
factory.RegisterFitPredicate("PodFitsHostPorts", predicates.PodFitsHostPorts)
最后,可以在 --policy-config-file 把自定义的过滤函数写进去,kube-scheduler 运行的时候就能执行你编写调度器的逻辑了。
自定义优先级函数的过程和这个过滤函数类似,就不赘述了。
3.3 编写自己的调度器
除了在 kube-scheduler 已有的框架中进行定制化外,kubernetes 还允许你重头编写自己的调度器组件,并在创建资源的时候使用它。多个调度器可以同时运行和工作,只要名字不冲突就行。
使用某个调度器就是在 pod 的 spec.schedulername 字段中填写上调度器的名字。kubernetes 提供的调度器名字是 default,如果自定义的调度器名字是 my-scheduler,那么只有当 spec.schedulername 字段是 my-scheduler 才会被后者调度。
NOTE:调取器的名字并没有统一保存在 apiserver 中进行统一管理,而是每个调取器去 apiserver 中获取和自己名字一直的 pod 来调度。也就是说,调度器是自己管理名字的,因此做到不冲突而且逻辑正确是每个调度器的工作。
虽然 kube-scheduler 的实现看起来很复杂,但是调度器最核心的逻辑是非常简单的。它从 apiserver 获取没有调度的 pod 信息和 node 信息,然后从节点中选择一个作为调度结果,然后向 apiserver 中写入 binding 资源。比如下面就是用 bash 编写的最精简调度器:
#!/bin/bash
SERVER='localhost:8001'
while true;
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"')
;
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$[ $RANDOM % $NUMNODES ]]}
curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "'$PODNAME'"}, "target": {"apiVersion": "v1", "kind"
: "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done
它通过 kubectl 命令从 apiserver 获取未调度的 pod(spec.schedulerName 是 my-scheduler,并且spec.nodeName 为空),同样地,用 kubectl 从 apiserver 获取 nodes 的信息,然后随机选择一个 node 作为调度结果,并写入到 apiserver 中。
当然要想编写一个生产级别的调度器,要完善的东西还很多,比如:
- 调度过程中需要保证 pod 是最新的,这个例子中每次调度 pod 的时候,它在 apiserver 中的内容可能已经发生了变化
- 调度过程需要考虑资源等因素(节点的资源利用率,存储和网络的信息等)
- 尽量提高调度的性能(使用并发来提高调度的性能)
虽然工作量很多,但是对于调度器要求非常高的话,编写自己的调度器也是不错的选择。
4. 总结
调度的过程是这样的:
- 客户端通过
kuberctl或者 apiserver 提交资源创建的请求,不管是 deployment、replicaset、job 还是 pod,最终都会产生要调度的 pod - 调度器从 apiserver 读取还没有调度的 pod 列表,循环遍历地为每个 pod 分配节点
- 调度器会保存集群节点的信息。对每一个 pod,调度器先过滤掉不满足 pod 运行条件的节点,这个过程是
Predicate - 通过过滤的节点,调度器会根据一定的算法給它们打分,确定它们的优先级顺序,并选择分数最高的节点作为结果
- 调度器根据最终选择出来的节点,把结果写入到 apiserver(创建一个 binding 资源)
相信阅读到这里,你对这几个步骤都已经非常清晰了。kube-scheduler 实现还是很赞的,目前已经达到生产级别的要求。但是我们还是能看到很多可以优化的地方,我能想到的一些点:
- 如果过滤的结果只有一个,应该可以直接使用这个节点,而不用再经过一遍 priority 的过程
- 目前每次只调度一个 pod,虽然中间调度过程利用并发来提高效率,但是如果能同时调度多个 pod,性能也会有提升。当然,如果要这样做,一定要考虑并发带来的共享数据的处理方法,代码的复杂性也会增加
- 调度的时候没有考虑节点实际使用情况,只是考虑了所有 pods 请求的资源情况。大部分情况下,pod 请求的资源并不能完全被用到,如果能保证这部分资源也被充分利用就更好了。但是因为实际的资源利用率是动态的,而且会有峰值,最重要的是无法判断 pod 未来实际的资源使用情况,想做到这一点需要有更优的算法
- 没有填写请求资源的 pod 会对集群带来影响。当前的实现中,如果 pod 没有在自己的配置中写上需要多少资源,scheduler 会把它申请的资源当做 0,这样会导致误判,导致集群不稳定。除了用户在创建的 pod 中都写上资源请求数量,目前还没有很好的方法来解决这个问题
没有调度器是完美的,但是相信 kubernetes scheduler 会在未来得到不断优化,变得越来越好。
5. 参考资料
- The Kubernetes Scheduler
- A toy kubernetes scheduler
- Scheduling your kubernetes pod with elixir
- KubeCon EU 2016: A Practical Guide to Container Scheduling
- The evolution of cluster scheduler architectures.
- Improving Kubernetes Scheduler Performance:CoreOS 团队如何对 kubernetes 进行性能分析和调优
- Kubernetes Scheduler 源码分析 - Walton Wang
