什么是 Knative?
knative 是谷歌开源的 serverless 架构方案,旨在提供一套简单易用的 serverless 方案,把 serverless 标准化。目前参与的公司主要是 Google、Pivotal、IBM、Red Hat,2018年7月24日才刚刚对外发布,当前还处于快速发展的阶段。
这是 Google Cloud Platform 宣布 knative 时给出的介绍:
Developed in close partnership with Pivotal, IBM, Red Hat, and SAP, Knative pushes Kubernetes-based computing forward by providing the building blocks you need to build and deploy modern, container-based serverless applications.
可以看出,knative 是为了解决容器为核心的 serverless 应用的构建、部署和运行的问题。
serverless 的概念已经出现蛮久了,为了理解 serverless, 可以从应用开发者的角度来看,使用 serverless 框架之后,应用开发者的整个操作流程就变成了:
~ # 编写 code 和 configuration 文件
~ # faascli build
~ # faascli deploy
~ # curl http://myapp.com/hello
hello, world from Awesome FaaS App!
可以看到用户只需要编写代码(或者函数),以及配置文件(如何 build、运行以及访问等声明式信息),然后运行 build 和 deploy 就能把应用自动部署到集群(可以是公有云,也可以是私有的集群)。
其他事情都是 serverless 平台(比如这里的 knative)自动处理的,这些事情包括:
- 自动完成代码到容器的构建
- 把应用(或者函数)和特定的事件进行绑定:当事件发生时,自动触发应用(或者函数)
- 网络的路由和流量控制
- 应用的自动伸缩
和标准化的 FaaS 不同(只运行特定标准的 Function 代码),knative 期望能够运行所有的 workload : traditional application、function、container。
knative 建立在 kubernetes 和 istio 平台之上,使用 kubernetes 提供的容器管理能力(deployment、replicaset、和 pods等),以及 istio 提供的网络管理功能(ingress、LB、dynamic route等)。
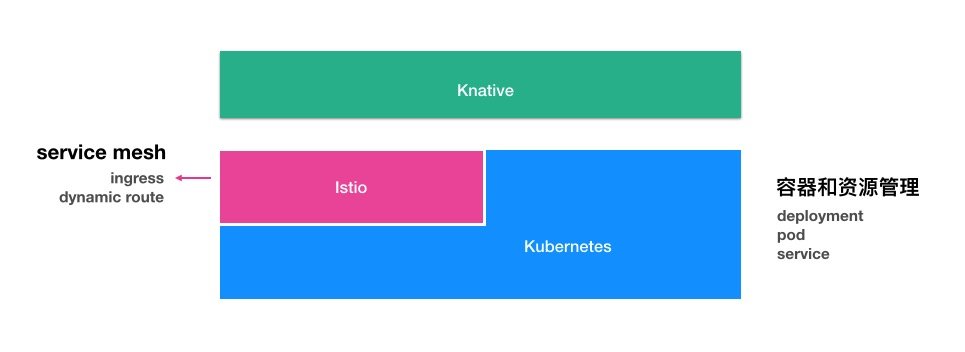
knative 核心概念和原理
为了实现 serverless 应用的管理,knative 把整个系统分成了三个部分:
- Build:构建系统,把用户定义的函数和应用 build 成容器镜像
- Serving:服务系统,用来配置应用的路由、升级策略、自动扩缩容等功能
- Eventing:事件系统,用来自动完成事件的绑定和触发
Build 构建系统
build 的功能是把用户的代码自动化构建成容器镜像,初次听起来很奇怪,有了 docker 之后有一个 Dockerfile 不就能构建容器了吗?为什么还需要一个新的 Build 系统?
Knative 的特别之处在于两点:一是它的构建完全是在 kubernetes 中进行的,和整个 kubernetes 生态结合更紧密;另外,它旨在提供一个通用的标准化的构建组件,可以作为其他更大系统中的一部分。
正如官方文档中的说的那样,是为了定义标准化、可移植、可重用、性能高效的构建方法:
The goal of a Knative build is to provide a standard, portable, reusable, and performance optimized method for defining and running on-cluster container image builds.
Knative 提供了 Build CRD 对象,让用户可以通过 yaml 文件定义构建过程。一个典型的 Build 配置文件如下:
apiVersion: build.knative.dev/v1alpha1
kind: Build
metadata:
name: example-build
spec:
serviceAccountName: build-auth-example
source:
git:
url: https://github.com/example/build-example.git
revision: master
steps:
- name: ubuntu-example
image: ubuntu
args: ["ubuntu-build-example", "SECRETS-example.md"]
steps:
- image: gcr.io/example-builders/build-example
args: ['echo', 'hello-example', 'build']
其中,serviceAccountName 是构建过程中需要用到的密码和认证信息(比如连接到 git repo 的 SSH keys、push 镜像到 registry 的用户名和密码等);source 是代码信息,比如这里的 git 地址和分支;steps 是真正运行过程中的各个步骤。
这个示例中的步骤只是作为 demo,真正的构建过程一般是 pull 代码、 build 镜像和 push镜像到 registry 等逻辑。
因为大部分的构建过程都是一致的,因此 knative 还提供了 Build template 的概念,
Build template 封装了预先定义好的构建过程(就是封装了上面的 steps 过程),并提供了非常简单的配置参数来使用。
使用 build template 构建容器镜像就更简单了,只需要提供代码的地址和镜像名字即可,比如下面是使用 Google kaniko 模板构建 github 源码的 yaml 文件(需要在代码根目录存在 Dockerfile 文件):
apiVersion: build.knative.dev/v1alpha1
kind: Build
metadata:
name: kaniko-build
spec:
serviceAccountName: build-bot
source:
git:
url: https://github.com/my-user/my-repo
revision: master
template:
name: kaniko
arguments:
- name: IMAGE
value: us.gcr.io/my-project/my-app
Serving:服务系统
serving 的核心功能是让应用运行起来提供服务。
虽然听起来很简单,但这里包括了很多的事情:
- 自动化启动和销毁容器
- 根据名字生成网络访问相关的 service、ingress 等对象
- 监控应用的请求,并自动扩缩容
- 支持蓝绿发布、回滚功能,方便应用发布流程
knative serving 功能是基于 kubernetes 和 istio 开发的,它使用 kubernetes 来管理容器(deployment、pod),istio 来管理网络路由(VirtualService、DestinationRule)。
因为 kubernetes 和 istio 本身的概念非常多,理解和管理起来比较困难,knative 在此之上提供了更高一层的抽象(这些对应是基于 kubernetes 的 CRD 实现的)。这些抽象出来的概念对应的关系如下图:
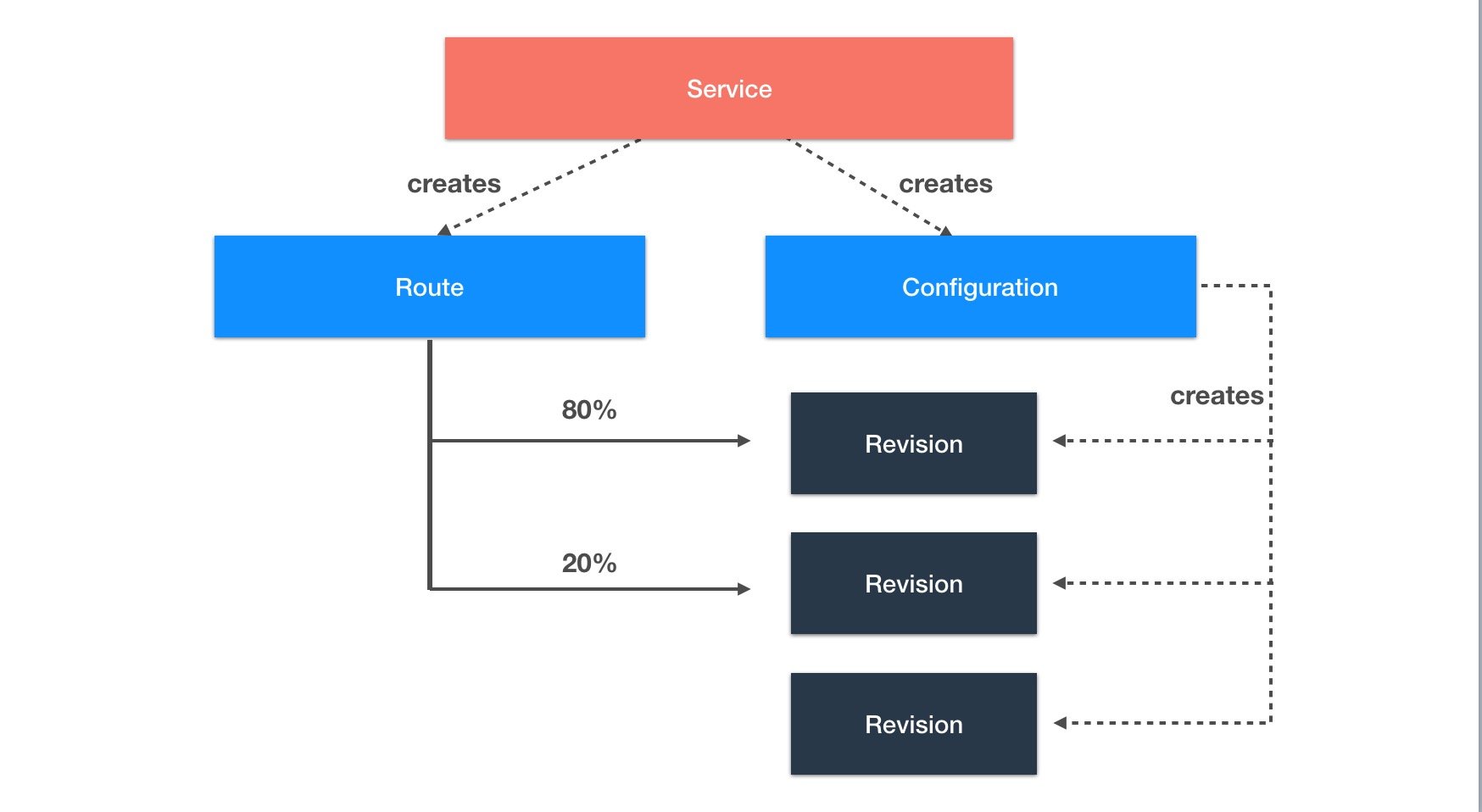
- Configuration:应用的最新配置,也就是应用目前期望的状态,对应了 kubernetes 的容器管理(deployment)。每次应用升级都会更新 configuration,而 knative 也会保留历史版本的记录(图中的 revision),结合流量管理,knative 可以让多个不同的版本共同提供服务,方便蓝绿发布和滚动升级
- Route:应用的路由规则,也就是进来的流量如何访问应用,对应了 istio 的流量管理(VirtualService)
- Service:注意这里不是 kubernetes 中提供服务发现的那个 service,而是 knative 自定义的 CRD,它的全称目前是
services.serving.knative.dev。单独控制 route 和 configuration 就能实现 serving 的所有功能,但knative 更推荐使用 Service 来管理,因为它会自动帮你管理 route 和 configuration
一个 hello world 的 serving 配置如下所示:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
image: docker.io/{username}/helloworld-go
env:
- name: TARGET
value: "Go Sample v1"
看起来和 kubernetes 的 pod 定义非常类似,但是它会帮你管理 deployment、ingress、service discovery、auto scaling……从这个角度来看,可以认为 knative 提供了更高的抽象,自动帮你封装掉了 kubernetes 和 istio 的实现细节。
下面这张图介绍了 knative serving 各组件之间的关系:
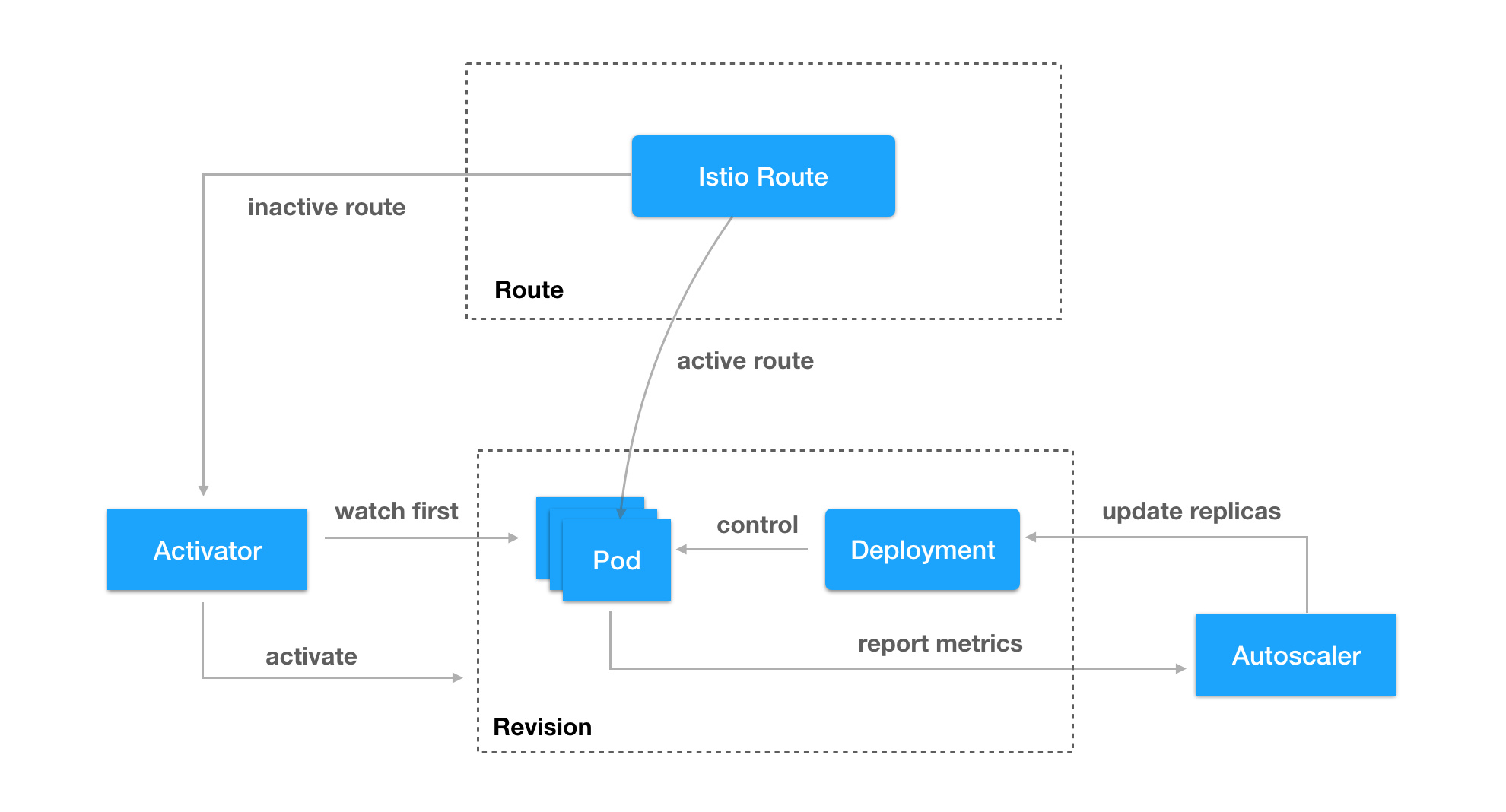
- 可以看到,每个 revision 对应了一组 deployment 管理的 pod
- pod 会自动汇报 metrics 数据到 autoscaler,autoscaler 会根据请求量和资源使用情况修改 deployment 的 replicas 数量,从而实现自动扩缩容。serverless 一个重要的特定是它会 scale to 0 的,也就是当应用没有流量访问时,它会自动销毁所有的 pod
- activator 比较有趣,它是为了处理 scale to 0 而出现的。当某个 revision 后面的 pod 缩容到 0 时,route 的流量会指向 activator,activator 接收到请求之后会自动拉起 pod,然后把流量转发过去
- route 对象对应了 istio 的 DestinationRoute 和 VirtualService,决定了访问应用的流量如何路由
Eventing:事件系统
serving 系统实现的功能是让应用/函数能够运行起来,并且自动伸缩,那什么时候才会调用应用呢?除了我们熟悉的正常应用调用之外,serverless 最重要的是基于事件的触发机制,也就是说当某件事发生时,就触发某个特定的函数。
事件概念的出现,让函数和具体的调用方能够解耦。函数部署出来不用关心谁会调用它,而事件源触发也不用关心谁会处理它。
Note:目前 serverless 的产品和平台很多,每个地方支持的事件来源以及对事件的定义都是不同的(比如 AWS Lambda 支持很多自己产品的事件源)。Knative 自然也会定义自己的事件类型,除此之外,knative 还联合 CNCF 在做事件标准化的工作,目前的产出是 CloudEvents 这个项目。
为了让整个事件系统更有扩展性和通用性,knative 定义了很多事件相关的概念。我们先来介绍一下:
- EventSource:事件源,能够产生事件的外部系统
- Feed:把某种类型的 EventType 和 EventSource 和对应的 Channel 绑定到一起
- Channel:对消息实现的一层抽象,后端可以使用 kafka、RabbitMQ、Google PubSub 作为具体的实现。channel name 类似于消息集群中的 topic,可以用来解耦事件源和函数。事件发生后 sink 到某个 channel 中,然后 channel 中的数据会被后端的函数消费
- Subscription:把 channel 和后端的函数绑定的一起,一个 channel 可以绑定到多个knative service
它们之间的关系流程图如下:
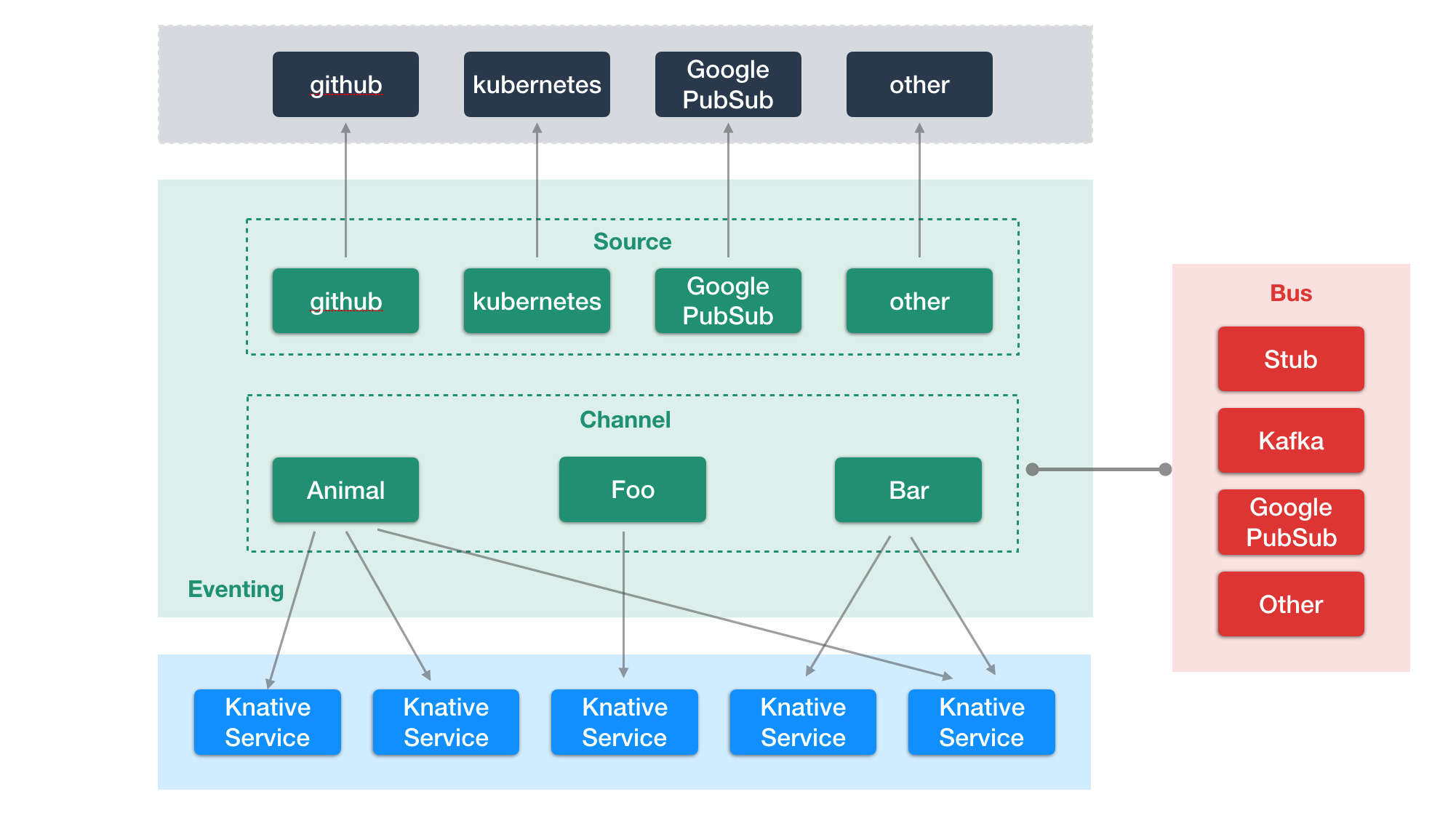
Bus 是 knative 内部的事件存储层,用户可以选择自己感兴趣的实现,目前支持的方式有:Stub(在内存中实现的简单消息系统)、Kafka、Google PubSub。如果想要事件能够正常运行,必须在 knative 集群中安装其中一个 bus 实现方式。
有了 bus 之后,我们就可以监听外部的事件了。目前支持的事件源有三个:github(比如 merge 事件,push 事件等),kubernetes(events),Google PubSub(消息系统),后面还会不断接入更多的事件源。
如果要想监听对应的事件源,需要在 knative 中部署一个 source adaptor 的 pod,它负责从外部的系统中读取事件。
读取后的事件,会根据用户配置的 Feed 对象(里面包括了事件源和 channel 的对应关系),找到对应的 channel,然后把消息发送到这个 channel 中(channel 的消息最终是存储在后端的 bus 系统里的)。
然后,knative 会根据 subscription 的配置,不断从 channel 中读取事件,然后把事件作为参数调用对应的函数,从而完成了整个事件的流程。
Knative 目前的状态
knative 是 2018 年 7月才刚刚对外开放,虽然内部已经开发一段时间,但是目前还处于非常早前的阶段(从支持的事件源和 bus就能看出来)。目前代码还不稳定,很多实现都是 hard-coded。
knative 也是脱产于 google 和 CNCF,因此整个社区运行方式和目标与之前的 kubernetes 以及 istio 非常相似。社区根据组件分成多个 Working Group,每个 Group 独立负责自己的功能,所有的开源活动(文档、视频、代码)都是开放的。另外,CloudEvents 作为 knative 依赖的标准,目标也是成为 CRI、CNI、CSI 这种类似的标准。
knative 社区目前非常活跃,以 github.com/knative/serving 项目为例,一个月已经有 600+ star,目前有 60+ contributor,900+ commits,而且入门的文档和教程都已经非常全面。
Knative 应用场景和思考
knative 基于 kubernetes 和 istio 的 serverless 开源实现,目标是提供更高层次的抽象,让开发者无需关注基础设施(虚拟机或者容器,网络配置,容量规划),而专注于业务代码即可。更多关于 knative 的使用场景可以参考 AWS Lambda 或者其他相关的文档,这里不再赘述,主要讲讲 knative 目前的局限性或者问题:
1. 性能问题
性能问题一直是 serverless 被人诟病的一点,也是目前它不能广泛用于应用服务上的决定性原因。互联网的应用大多数有高并发、高性能的要求,serverless 整个网络链路很长,容器启停需要额外的时间,还无法满足互联网应用的要求。
针对这一点,很多 serverless 框架也在不断地做改进,比如不断精简容器的启动时间、容器启动之后会做缓存等,比如 nuclio 就宣称自己的平台比 AWS Lambda 要快 10 倍以上。
相信随着 serverless 的不断演进,性能问题会不断优化,至于能不能达到互联网应用的要求,还要时间给我们答案。
2. 是否需要 istio 这一层?
基于 kubernetes 的 serverless 组件非常多,比如 kubeless。但是基于 kubernetes 同时又基于 istio,目前 knative 还是第一个这么做的。
有些人的疑问在于,knative 真的有必要基于 istio 来做吗?对于这个问题,我个人的看法是必要的。
虽然 istio 才刚刚release 1.0 版本,但是它作为集群基础设施通用网络层的地位已经开始显露,相信在未来的发展中接受度会越来越大,并逐渐巩固自己的地位。虽然现阶段来说,很多人并不非常熟悉 istio 的情况,但是从长远角度来看,这一点将是 knative 的一个优势所在。
另外,基于 istio 构建自己的 serverless 服务,也符合目前软件行业不要重复造轮子的思路。istio 在集群的网络管理方面非常优秀(智能路由、负载均衡、蓝绿发布等),基于 istio 来做可以让 knative 不用重复工作就能直接使用 istio 提供的网络通用功能。
3. 系统复杂度
这一点和上面类似,knative 下面已经有两个非常复杂的平台:kubernetes 和 istio。这两个平台的理解、构建、运维本身就很复杂,如今又加上 knative 整个平台,需要了解的概念都要几十个,更不要提落地过程中会遇到的各种问题。
对于公有云来说,kubernetes 和 istio 这些底层平台可以交给云供应商来维护(比如 google Function),但是对于内部构建来说,这无疑提高了整个技术门槛,对系统管理人员的要求更高。
如何安装部署整个集群?如何对集群做升级?出现问题怎么调试和追踪?怎么更好地和内部的系统对接?这些系统的最佳实践是什么?怎么做性能优化?所有这些问题都需要集群管理人员思考并落实。
4. 函数的可运维性?
相对于编写微服务来说,单个函数的复杂度已经非常低,但是当非常多的函数需要共同工作的时候,如何管理这些函数就成了一个必须解决的问题。
- 如何快速找到某个函数?
- 如何知道一个函数的功能是什么?接受的参数是什么?
- 怎么保证函数的升级不会破坏原有的功能?升级之后如何回滚?怎么记录函数的历史版本方面追溯?
- 当有多个函数需要同时工作的时候,怎么定义它们之间的关系?
- 函数出现问题的时候如何调试?
对于函数的运维,一般的 serverless 平台(包括 knative)都提供了 logging、metrics、tracing 三个方面的功能。默认情况下,knative 使用 EFK(Elasticsearch、Fluent、Kibana)来收集、查找和分析日志;使用 prometheus + grafana 来收集和索引、展示 metrics 数据;使用 jaeger 来进行调用关系的 tracing。
针对 serverless 衍生出来的运维工具和平台还不够多,如何调试线上问题还没有看到非常好的解决方案。
5. knative 成熟度
最后一点是关于 knative 成熟度的,前面已经提到,knative 目前刚出现不久。虽然整个框架和设计都已经搭好了,但是很多实现都比较初级。这里提几点来说:
- 为了实现 autoscaling,knative 在每个 pod 中添加一个叫做 queue proxy 的代理,它会自动把请求的 metrics 发送给 autoscaler 组件作为参考。这样一来,整个网络链路上又多了一层,对整个性能势必会有影响,未来的打算是直接使用 envoy sidecar 来替换掉 queue proxy
- 支持的事件源和消息系统还很有限,外部事件只支持 github、kubernetes 和 Google PubSub。 这个问题可以慢慢扩展,knative 本身会实现很常用的事件类型,自定义的事件源用户可以自己实现
- 目前还没有函数的 pipeline 管理(类似 AWS Lambda Step Functions),多个函数如何协作并没有自己处理。虽然没有在官方文档中看到这方面的 roadmap,但是以后一定会有这方面的功能(不管是 knative 本身来做,还是社区作为工具补充来实现)
这方面的问题都不是大事情,随着 knative 版本的迭代,在很快的时间都能够解决。
参考资料
- Google Cloud Platform 宣布 Knative 发布的博客文章: Google Cloud Platform Blog: Bringing the best of serverless to you
- the Newstack 上非常好的科普文章: Knative Enables Portable Serverless Platforms on Kubernetes, for Any Cloud - The New Stack
- Serving 的设计理念:https://docs.google.com/presentation/d/1CbwVC7W2JaSxRyltU8CS1bIsrIXu1RrZqvnlMlDaaJE/edit#slide=id.g32c674a9d1_0_5
- knative 官方文档:GitHub - knative/docs: Documentation for users of Knative components
- Google Cloud Next 2018 大会上宣布 knative 的视频 presentation: Kubernetes, Serverless, and You (Cloud Next ’18) - YouTube
- Google Cloud Knative 产品页面,目前只有最简单的介绍和文档链接
