TL;DR
介绍
在 openstack 中,scheduler 负责从宿主机(运行 nova-compute 的节点)中根据一系列的算法和参数(CPU 核数,可用 RAM,镜像类型等 )选择出来一个,来部署虚拟机(instance)。openstack 官方网站上这张经典的图可以直观地看到 scheduler 的两个步骤:过滤(filter) + 权重计算(weighting)。
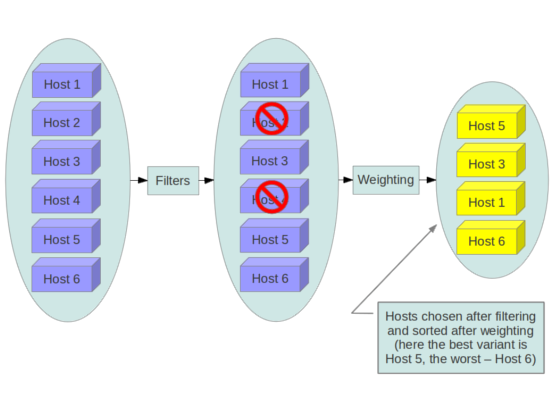
简单来说,过滤就是把不符合条件的宿主机去除掉,权重计算就是把剩下的主机根据某个值排序。如果这个过程中出错,就会报 NoValidHost 这个“万能错误”(horizon 上部署机器这个错误出现的几率很高,而且原因是多种多样的)。
源码分析
注:下面所有分析的源码都是在 Icehouse 版本进行的,其他版本可能会有不同。
代码结构
scheduler 相关的代码主要放在 nova/scheduler/ 这个文件夹下面,外加 nova/filters.py 和 nova/weights.py 这两个辅助文件。
文件的目录结构如下:
nova/scheduler
├── __init__.py
├── baremetal_host_manager.py
├── caching_scheduler.py
├── chance.py
├── driver.py
├── filter_scheduler.py
├── filters
│ ├── __init__.py
│ ├── affinity_filter.py
│ ├── aggregate_image_properties_isolation.py
│ ├── aggregate_instance_extra_specs.py
│ ├── aggregate_multitenancy_isolation.py
│ ├── all_hosts_filter.py
│ ├── availability_zone_filter.py
│ ├── compute_capabilities_filter.py
│ ├── compute_filter.py
│ ├── core_filter.py
│ ├── disk_filter.py
│ ├── extra_specs_ops.py
│ ├── image_props_filter.py
│ ├── io_ops_filter.py
│ ├── isolated_hosts_filter.py
│ ├── json_filter.py
│ ├── metrics_filter.py
│ ├── num_instances_filter.py
│ ├── pci_passthrough_filter.py
│ ├── ram_filter.py
│ ├── retry_filter.py
│ ├── trusted_filter.py
│ └── type_filter.py
├── host_manager.py
├── manager.py
├── rpcapi.py
├── scheduler_options.py
├── utils.py
└── weights
├── __init__.py
├── metrics.py
└── ram.py
manager.py 这个文件中主要处理 Scheduler 服务接受到的消息,除了 run_instance 之外,还有 live_migration、prep_resize。 这些操作一般会直接调用自身的 Scheduler 去执行,也有一部分会直接发送消息给 compute 服务去做。
host_manager.py 是管理 zone 里面宿主机资源的,里面有两个类:
HostState封装了一台宿主机的资源情况,比如可用的内存,已用的内存,已用的硬盘,可用的硬盘,运行的 instance 个数,宿主机 ip,宿主机类型等等信息,还包含了一些方法来更新这些值。HostManager: 管理宿主机的类,主要功能是:调用 filter 和 weight 的 handler 和配置里定义的对应的类来实现调度,主要的方法有:get_all_host_states(self, context): 返回能发现的所有宿主机信息,返回值是 HostState 列表get_filters_hosts(self, hosts, filter_properties):返回符合过滤条件的所有宿主机get_weighted_hosts(self, hosts, weight_properties):对传进去的宿主机进行权重计算,返回排序好的列表
filters/__init__.py 定义了两个重要的类:
BaseHostFilter:所有的 filter 都要继承这个基类来实现自己的过滤功能,里面有两个方法:host_passes(self, host_state, filter_properties):如果 HostState 能够通过过滤函数,就返回 True,否则返回 False_filter_one(self, obj, filter_properties):调用host_passes,判断 obj 是否能通过过滤
HostFilterHandler:直接继承自nova/filters.py:BaseFiltrHandler这个类,最重要的方法是get_filtered_objects(self, filter_classes, objs, filter_properties, index=0),对每台 instance 调用 各个 filter_classes(可能有些 filter 只在第一次运行),最后返回通过的对象
weights/__init__.py 也定义了两个重要的类:
BaseHostWeigher:直接继承自nova/weights.py:BaseWeigher,所有具体的子类都要继承这个类,并实现自己的_weigh_object(self, host_state, weight_properties)方法,来对宿主机计算权重。HostWeightHandler:直接继承自nova/weights.py:BaseWeightHandler类,最重要的方法是get_weighted_objects(self, weigher_classes, obj_list, weighing_properties),用来调用各个权重类来计算总的权重,并返回排序后的结果
weights/ram.py:根据宿主机目前可用内存进行权重计算weights/metrics.py:根据自定义的 metrics 进行权重计算
执行流程
主要的文件和类都已经介绍得差不多了,我们来把这些东西串一下,看看实际调度怎么工作的:
- nova-scheduler 服务从 MQ 中接收到创建虚拟机的请求,调用
manger.py:SchedulerManager的run_instance方法 run_instance中会调用自己 driver(默认是filter_scheduler.py:FilterScheduler) 的schedule_run_instance方法来调度schedule_run_instance会调用自身类里_schedule方法来进行过滤和计算权重_schedule方法会调用host_manager.py:HostManager的get_all_host_states来获取所有可用的宿主机,调用get_filtered_hosts来对宿主机进行过滤,调用get_weighed_hosts对宿主机进行权重排序。如果有多个 instances 要创建,会循环为每个 instance 都跑一遍,获得最终的宿主机get_filtered_hosts会先对ignore_hosts,force_hosts和force_nodes属性进行过滤,然后调用self.filter_handler.get_filtered_objects方法。默认的 filter_handler 是scheduler/filters/__init__.py:HostFilterHandler,它直接继承了nova/filtes.py:BaseFilterHandler类的get_filted_objects方法,这个方法会调用所有的 filter_class,执行最终的过滤- 类似的,
get_weighed_hosts直接调用self.weight_handler.get_weighed_objects方法,默认的 weight_handler 是scheduler/weights/__init__.py:HostWeightHandler,它直接继承了nova/weights.py:BaseWeightHandler的get_weighed_objects,这个方法是最终计算权重并排序的地方 - 得到了最终的列表,就循环给 nova-compute 发消息,里面带上刚选择的宿主机,并更新数库中 instance 的数据
- nova-compute 接收到消息,开始自己的逻辑,部署一台虚拟机
filter_scheduler
我们重点讲一下 Scheduler,所有的 Scheduler 的基类是 nova/scheduler/driver.py:Scheduler:
class Scheduler(object):
"""The base class that all Scheduler classes should inherit from."""
def __init__(self):
self.host_manager = importutils.import_object(
CONF.scheduler_host_manager)
self.servicegroup_api = servicegroup.API()
def run_periodic_tasks(self, context):
"""Manager calls this so drivers can perform periodic tasks."""
pass
def hosts_up(self, context, topic):
"""Return the list of hosts that have a running service for topic."""
services = db.service_get_all_by_topic(context, topic)
return [service['host']
for service in services
if self.servicegroup_api.service_is_up(service)]
def schedule_run_instance(self, context, request_spec,
admin_password, injected_files,
requested_networks, is_first_time,
filter_properties, legacy_bdm_in_spec):
"""Must override schedule_run_instance method for scheduler to work."""
msg = _("Driver must implement schedule_run_instance")
raise NotImplementedError(msg)
def select_destinations(self, context, request_spec, filter_properties):
"""Must override select_destinations method.
:return: A list of dicts with 'host', 'nodename' and 'limits' as keys
that satisfies the request_spec and filter_properties.
"""
msg = _("Driver must implement select_destinations")
raise NotImplementedError(msg)
子类需要实现 schedule_run_instance 和 select_destionations 方法来做具体的调度。目前有三种不同的实现:
chance.py:ChanceScheduler:随机选择一台宿主机,只要上面 nova-compute 服务正常,并且不再ignore_hosts列表里filter_scheduler.py:FilterScheduler:先过滤后计算权重的调度模式,用户可以扩展自己的 filtercaching_scheduler.py:CachingScheduler:在 FilterScheduler 上面又封装了一层,将所有 host 信息保存到内存中,然后定时通过 DB 来信息来更新这个列表,这样下次调度的时候使用缓存的数据
默认使用 FilterScheduler,也是我们下面重点介绍的部分。刚刚提到,它最重要的方法是 schedule_run_isntance:
def schedule_run_instance(self, context, request_spec,
admin_password, injected_files,
requested_networks, is_first_time,
filter_properties, legacy_bdm_in_spec):
"""This method is called from nova.compute.api to provision
an instance. We first create a build plan (a list of WeightedHosts)
and then provision.
Returns a list of the instances created.
"""
payload = dict(request_spec=request_spec)
self.notifier.info(context, 'scheduler.run_instance.start', payload)
instance_uuids = request_spec.get('instance_uuids')
LOG.info(_("Attempting to build %(num_instances)d instance(s) "
"uuids: %(instance_uuids)s"),
{'num_instances': len(instance_uuids),
'instance_uuids': instance_uuids})
LOG.debug(_("Request Spec: %s") % request_spec)
weighed_hosts = self._schedule(context, request_spec,
filter_properties, instance_uuids)
# NOTE: Pop instance_uuids as individual creates do not need the
# set of uuids. Do not pop before here as the upper exception
# handler fo NoValidHost needs the uuid to set error state
instance_uuids = request_spec.pop('instance_uuids')
# NOTE(comstud): Make sure we do not pass this through. It
# contains an instance of RpcContext that cannot be serialized.
filter_properties.pop('context', None)
for num, instance_uuid in enumerate(instance_uuids):
request_spec['instance_properties']['launch_index'] = num
try:
try:
weighed_host = weighed_hosts.pop(0)
LOG.info(_("Choosing host %(weighed_host)s "
"for instance %(instance_uuid)s"),
{'weighed_host': weighed_host,
'instance_uuid': instance_uuid})
except IndexError:
raise exception.NoValidHost(reason="")
self._provision_resource(context, weighed_host,
request_spec,
filter_properties,
requested_networks,
injected_files, admin_password,
is_first_time,
instance_uuid=instance_uuid,
legacy_bdm_in_spec=legacy_bdm_in_spec)
except Exception as ex:
# NOTE(vish): we don't reraise the exception here to make sure
# that all instances in the request get set to
# error properly
driver.handle_schedule_error(context, ex, instance_uuid,
request_spec)
# scrub retry host list in case we're scheduling multiple
# instances:
retry = filter_properties.get('retry', {})
retry['hosts'] = []
self.notifier.info(context, 'scheduler.run_instance.end', payload)
上面这段代码可以简单分成三个部分:
- 准备和构造工作
- 调用
_schedule方法进行调度 - 循环调度的结果,调用
_provision_resource进行部署
_provision_resource 的主要工作就是更新宿主机的资源情况,向 compute 发送部署消息,我们来重点看一下 _schedule:
def _schedule(self, context, request_spec, filter_properties,
instance_uuids=None):
"""Returns a list of hosts that meet the required specs,
ordered by their fitness.
"""
elevated = context.elevated()
instance_properties = request_spec['instance_properties']
instance_type = request_spec.get("instance_type", None)
update_group_hosts = self._setup_instance_group(context,
filter_properties)
config_options = self._get_configuration_options()
# check retry policy. Rather ugly use of instance_uuids[0]...
# but if we've exceeded max retries... then we really only
# have a single instance.
properties = instance_properties.copy()
if instance_uuids:
properties['uuid'] = instance_uuids[0]
self._populate_retry(filter_properties, properties)
filter_properties.update({'context': context,
'request_spec': request_spec,
'config_options': config_options,
'instance_type': instance_type})
self.populate_filter_properties(request_spec,
filter_properties)
# Find our local list of acceptable hosts by repeatedly
# filtering and weighing our options. Each time we choose a
# host, we virtually consume resources on it so subsequent
# selections can adjust accordingly.
# Note: remember, we are using an iterator here. So only
# traverse this list once. This can bite you if the hosts
# are being scanned in a filter or weighing function.
hosts = self._get_all_host_states(elevated)
selected_hosts = []
if instance_uuids:
num_instances = len(instance_uuids)
else:
num_instances = request_spec.get('num_instances', 1)
for num in xrange(num_instances):
# Filter local hosts based on requirements ...
hosts = self.host_manager.get_filtered_hosts(hosts,
filter_properties, index=num)
if not hosts:
# Can't get any more locally.
break
LOG.debug(_("Filtered %(hosts)s"), {'hosts': hosts})
weighed_hosts = self.host_manager.get_weighed_hosts(hosts,
filter_properties)
LOG.debug(_("Weighed %(hosts)s"), {'hosts': weighed_hosts})
scheduler_host_subset_size = CONF.scheduler_host_subset_size
if scheduler_host_subset_size > len(weighed_hosts):
scheduler_host_subset_size = len(weighed_hosts)
if scheduler_host_subset_size < 1:
scheduler_host_subset_size = 1
chosen_host = random.choice(
weighed_hosts[0:scheduler_host_subset_size])
selected_hosts.append(chosen_host)
# Now consume the resources so the filter/weights
# will change for the next instance.
chosen_host.obj.consume_from_instance(instance_properties)
if update_group_hosts is True:
filter_properties['group_hosts'].add(chosen_host.obj.host)
return selected_hosts
这段代码也可以简单分成几部分:
- 更新和完善
filter_properties - 获取所有宿主机信息
- 为每个 instance 循环调用 filter 和 weigh 方法
- 获取最终的宿主机,并更新宿主机资源信息
filter 部分最终会调用 nova/filters.py:BaseFilterHandler 定义的方法:
def get_filtered_objects(self, filter_classes, objs,
filter_properties, index=0):
list_objs = list(objs)
LOG.debug(_("Starting with %d host(s)"), len(list_objs))
for filter_cls in filter_classes:
cls_name = filter_cls.__name__
filter = filter_cls()
if filter.run_filter_for_index(index):
objs = filter.filter_all(list_objs,
filter_properties)
if objs is None:
LOG.debug(_("Filter %(cls_name)s says to stop filtering"),
{'cls_name': cls_name})
return
list_objs = list(objs)
if not list_objs:
LOG.info(_("Filter %s returned 0 hosts"), cls_name)
break
LOG.debug(_("Filter %(cls_name)s returned "
"%(obj_len)d host(s)"),
{'cls_name': cls_name, 'obj_len': len(list_objs)})
return list_objs
没什么好说的,就是把所有的 filters 都跑一遍,进去的是 objs 对象,返回能通过 filter 的 list_objs。每个 filter 都是调用 filter_all 方法,这个方法最终会调用 filter 的 host_passes,后面还会分析几个 filter 的代码。
类似的,权重计算过程也是调用所有的 weigh 类:
def get_weighed_objects(self, weigher_classes, obj_list,
weighing_properties):
"""Return a sorted (descending), normalized list of WeighedObjects."""
if not obj_list:
return []
weighed_objs = [self.object_class(obj, 0.0) for obj in obj_list]
for weigher_cls in weigher_classes:
weigher = weigher_cls()
weights = weigher.weigh_objects(weighed_objs, weighing_properties)
# Normalize the weights
weights = normalize(weights,
minval=weigher.minval,
maxval=weigher.maxval)
for i, weight in enumerate(weights):
obj = weighed_objs[i]
obj.weight += weigher.weight_multiplier() * weight
return sorted(weighed_objs, key=lambda x: x.weight, reverse=True)
不同的是,每个对象最终的权重是叠加起来的。为了防止某些 weigh 计算得到的值太夸张(比如你自定义了一个类,把权重结果设置得很大),在叠加之前还会调用 normalize 函数把值标准化到 [0, 1] 之间,算法也比较简单,会取出你给出的一组权重值的最大值和最小值,然后每个值变成:
(value - min) / (max - min)
这样就不会出现某个权重指标影响过大的问题。除此之外,每个权重指标还有一个 multiplier 的概念,就是你希望某个指标占的比重更大一点,而不是所有权重指标都一样。
filters
在 nova/scheduler/filters/__init__.py 文件中有一个类 BaseHostFilter:
class BaseHostFilter(filters.BaseFilter):
"""Base class for host filters."""
def _filter_one(self, obj, filter_properties):
"""Return True if the object passes the filter, otherwise False."""
return self.host_passes(obj, filter_properties)
def host_passes(self, host_state, filter_properties):
"""Return True if the HostState passes the filter, otherwise False.
Override this in a subclass.
"""
raise NotImplementedError()
这个类是所有具体 filter 的基类,子类需要实现自己的 host_passes 方法,我们先看一个简单的 filter:
class BaseRamFilter(filters.BaseHostFilter):
def _get_ram_allocation_ratio(self, host_state, filter_properties):
raise NotImplementedError
def host_passes(self, host_state, filter_properties):
"""Only return hosts with sufficient available RAM."""
instance_type = filter_properties.get('instance_type')
requested_ram = instance_type['memory_mb']
free_ram_mb = host_state.free_ram_mb
total_usable_ram_mb = host_state.total_usable_ram_mb
ram_allocation_ratio = self._get_ram_allocation_ratio(host_state,
filter_properties)
memory_mb_limit = total_usable_ram_mb * ram_allocation_ratio
used_ram_mb = total_usable_ram_mb - free_ram_mb
usable_ram = memory_mb_limit - used_ram_mb
if not usable_ram >= requested_ram:
LOG.debug(_("%(host_state)s does not have %(requested_ram)s MB "
"usable ram, it only has %(usable_ram)s MB usable ram."),
{'host_state': host_state,
'requested_ram': requested_ram,
'usable_ram': usable_ram})
return False
# save oversubscription limit for compute node to test against:
host_state.limits['memory_mb'] = memory_mb_limit
return True
filters/ram_filter.py 文件中定义的 BaseRamFilter 很简单,只要宿主机可分配的内存大于 instance 请求的内存,就返回 True,否则返回 False。类似的 DiskFilter 和 CoreFilter 都是同样的意思。这些简单的 filters 组合起来非常强大,可以满足很复杂的需求。
weights
所有的 weigh 类只要继承 schedule/weights/__ini__.py:BaseHostWeigher,实现自己的 _weigh_objects 就可以啦,比如 RamWeigher:
class RAMWeigher(weights.BaseHostWeigher):
minval = 0
def weight_multiplier(self):
"""Override the weight multiplier."""
return CONF.ram_weight_multiplier
def _weigh_object(self, host_state, weight_properties):
"""Higher weights win. We want spreading to be the default."""
return host_state.free_ram_mb
_weigh_object 返回一个数值,表示权重指标。另外一个 weigher 类是 MetricsWeigher:
class MetricsWeigher(weights.BaseHostWeigher):
def __init__(self):
self._parse_setting()
def _parse_setting(self):
self.setting = utils.parse_options(CONF.metrics.weight_setting,
sep='=',
converter=float,
name="metrics.weight_setting")
def weight_multiplier(self):
"""Override the weight multiplier."""
return CONF.metrics.weight_multiplier
def _weigh_object(self, host_state, weight_properties):
value = 0.0
for (name, ratio) in self.setting:
try:
value += host_state.metrics[name].value * ratio
except KeyError:
if CONF.metrics.required:
raise exception.ComputeHostMetricNotFound(
host=host_state.host,
node=host_state.nodename,
name=name)
else:
# We treat the unavailable metric as the most negative
# factor, i.e. set the value to make this obj would be
# at the end of the ordered weighed obj list
# Do nothing if ratio or weight_multiplier is 0.
if ratio * self.weight_multiplier() != 0:
return CONF.metrics.weight_of_unavailable
return value
返回所有自定义 metrics 与对应 ratio 的乘积和。
如果需要定制自己的调度算法,只要在 filters 或者 weights 文件夹下面添加一个文件,并修改一下配置文件就好了。
对了,还要提醒一件事:因为 filters 是逐个调用的,所以最好把过滤性强(能除去更多不符合条件宿主机)的放到配置项的最前面。
