最近在研究如何给应用添加合适的 metrics,用来分析应用的使用情况以及调试,整体思路是使用 promethues 收集数据,grafana 进行数据的展示。过程中发现了 node-exporter 项目,觉得可以直接拿来监控自己平时使用的 linux 机器,就有了这篇文章。
整个系统使用了三个组件:
- node-exporter:运行在主机上收集操作系统上各种数据的 agent,promethues 中称为 exporter
- prometheus:开源的时序数据库,作为数据存储和分析的中心
- grafana:数据展示分析界面,提供各种强大的 dashboard,可以从多个数据源读取数据,其中就包括 promethues
NOTE:所有的服务都是通过 docker 启动的,需要安装 docker 和 docker-compose,并熟悉它们的使用。
安装配置 promethues
promethues 最早是 soundcloud 开发的一款时序数据库,用来作为 metrics 数据收集和存储,目前已经成为 CNCF 基金会下面的一个项目,也是 kubernets 官方推荐的 metrics 收集和监控工具。
首先,我们创建一个 docker-compose.yml 文件,里面只包含 promethues 一个服务:
version: '2'
services:
prometheus:
image: prom/prometheus:v2.0.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- '9090:9090'
如果对 docker 和 docker-compose 熟悉的话,上面的内容容易理解:
- image 后面指定了使用的 promethues 容器镜像,该文件使用的是 v2.0.0 版本
- volumes 把当前目录下面的
prometheus.yml文件挂载到容器里,这样是因为后面会一直修改这个文件,利用 volume 挂载的方式比较灵活 - command 指定了 promethues 运行的命令行参数,这里只指定配置文件的位置,更多参数可以使用
--help来查看 - ports 把 promethues 服务监听的端口映射到主机上,这样可以直接访问主机端口使用它
其中比较重要的是 prometheus.yml 文件,它的内容如下:
global:
scrape_interval: 5s
external_labels:
monitor: 'my-monitor'
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
这个配置文件一共分为两个部分:global 和 scrape_configs,前者是全局的配置,如果后面的任务没有对特定配置项进行覆盖,这里的选项会生效。这里有两个配置项,scrape_interval 表示 promethues server 抓取的周期,如果太频繁会导致 promethues 压力比较大,如果太久,可能会导致某些关键数据漏掉,推荐根据每个任务的重要性和集群规模分别进行配置。
scrape_configs 配置了每个抓取任务,因此是一个列表,这里我们只有一个任务,那就是抓取 promethues 本身的 metrics。配置里面最重要的是 static_configs.targets,表示要抓取任务的 HTTP 地址,默认会在 /metrics url 出进行抓取,比如这里就是 http://localhost:9090/。 这是 prometheus 本身提供的监控数据,可以在浏览器中直接查看。
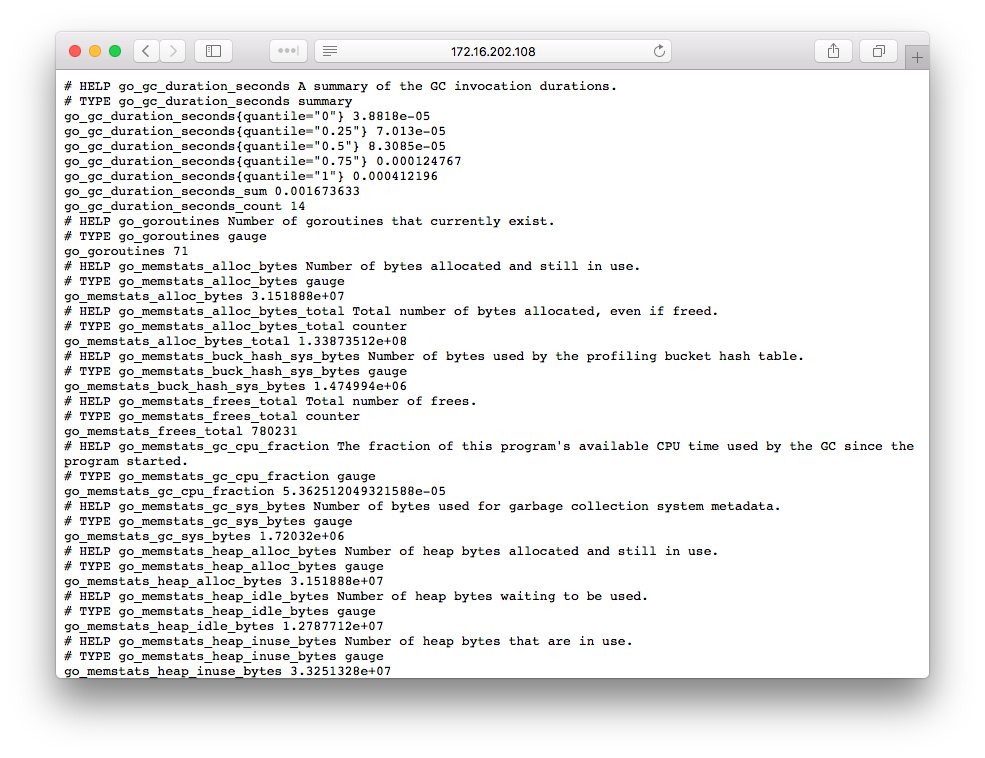
每个数据都是有一个名字和一系列称为 label 的键值对组成的,prometheus 在抓取数据的时候还会自动添加上 instance(节点的 host:port 标识) 和 job(任务名称) 两个 label 作为任务之间的区分。
这些数据本身没有时间信息,当 promethues 抓取的时候会自动添加上当时的时间戳。此外这些数据在客户端会分成四种不同的类型:counter、gauge、histogram 和 summary。更多关于 promethues metrics 数据类型的说明请查阅官方文档。
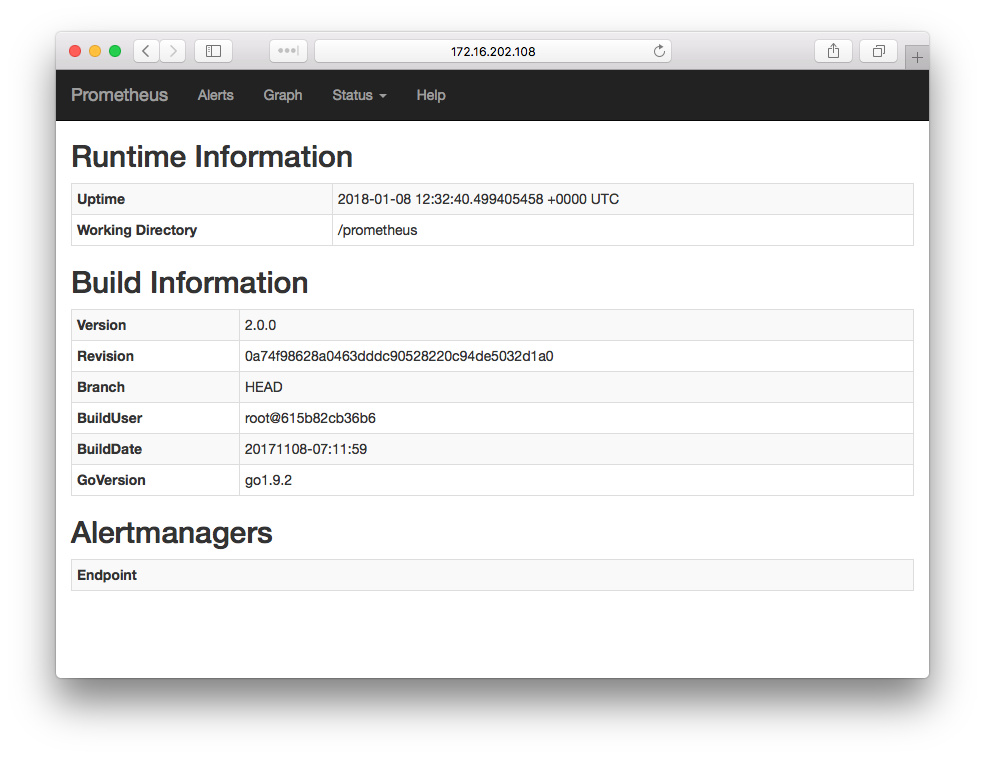
运行 docker-compose up -d 启动服务,然后在浏览器中打开 http://server-ip:9090/status 查看 promethues 运行的状态信息:
整个 promethues 体系的工作原理如下所示:
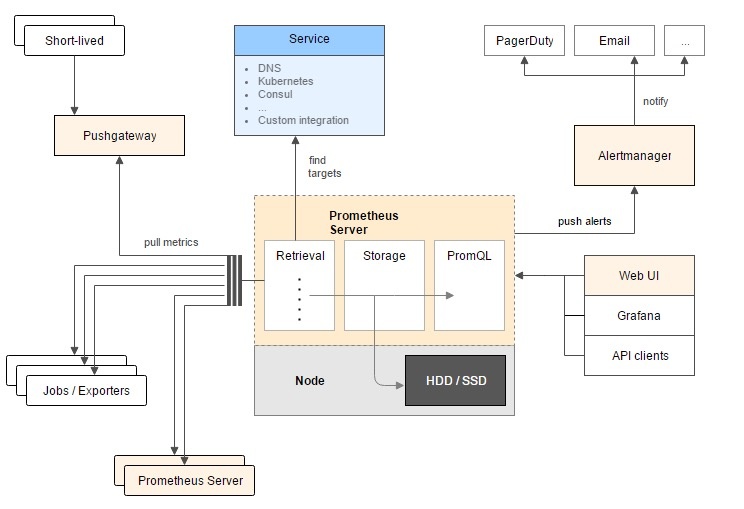
- promethues server 位于中心,负责时序数据的收集、存储和查询
- 左边是数据来源,promethues 统一采用拉取的模式(pull mode)从兼容的 HTTP 接口处获取数据,数据源可以分为三种
- 本身就暴露 promethues 可读取 metrics 数据的或者专门为某个组件编写的 exporter,称为 Jobs 或者 Exporters,比如 node exporter,HAProxy、Nginx、MySQL 等服务的 exporter
- 通过 push gateway 可以把原来 push 类型的数据转换成 pull 类型
- 其他 promethues server
- 上面是目标自动发现机制。对于生产的很多情况,手动配置所有的 metrics 来源可能会非常繁琐,所以 promethues 支持 DNS、kubernetes、Consul 等服务发现机制来动态地获取目标源进行数据抓取
- 右下方是数据输出,一般是用来进行 UI 展示,可以使用 grafana 等开源方案,也可以直接读取 promethues 的接口进行自主开发
- 右上方是告警部分,用户需要配置告警规则,一旦 alertManager 发现监控数据匹配告警规则,就把告警信息通过邮件、社交账号发送出去
使用 node exporter 收集监控数据
虽然监控 promethues 服务自身是件有趣而且有用的事情,但是我们的目标是监控 linux 主机。因为 promethues 只能从 HTTP 接口的某个地址来拉取监控数据,因此需要一个工具把 linux 提供的系统数据以 HTTP 服务的形式暴露出来。庆幸的是,promethues 官方社区有很多 exporter,它们负责把某个组件或者系统的 而监控数据以 promethues 能理解的方式暴露出来,其中 node exporter 就是导出 unix/linux 系统监控数据的工具。
grafana 主要是从 /proc 中读取 linux 提供的各种数据,修改 docker-compose.yml 文件,添加上 node-exporter 相关的内容,node-exporter 默认会监听在 9100 端口:
version: '2'
services:
prometheus:
image: prom/prometheus:v2.0.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- '9090:9090'
node-exporter:
image: prom/node-exporter:v0.15.2
ports:
- '9100:9100'
为了让 promethues 收集 node-exporter 的内容,我们需要在配置文件中加上一个单独的任务:
global:
scrape_interval: 5s
external_labels:
monitor: 'my-monitor'
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node resources'
scrape_interval: 10s
static_configs:
- targets:
- 'node-exporter:9100'
因为 docker-compose 会自动做服务到 IP 地址的解析,因此这里可以直接使用 node-exporter:9100 作为地址。
再次运行,确认 promethues 中 targets 列表中有 node-exporter。
安装配置 grafana
prometheus 自带的 web 界面可以用来查询配置内容、监控节点是否运行正常,也可以用来查询某个 metric 的数值,以及提供简单的图形化功能。但是它的图形化功能比较单一, 当有很多数据要同时进行展示时,就需要借助更强大的 dashboard 工具,比如这里要介绍的 grafana。
grafana 是一款强大的 dashboard 工具,界面设计很好看,功能强大,可配置性非常灵活。
同样,在 docker-compose.yml 文件中加入 grafana 服务:
version: '2'
services:
prometheus:
image: prom/prometheus:v2.0.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- '9090:9090'
node-exporter:
image: prom/node-exporter:v0.15.2
ports:
- '9100:9100'
grafana:
image: grafana/grafana:4.6.2
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=pass
depends_on:
- prometheus
ports:
- '3000:3000'
volumes:
grafana_data: {}
prometheus_data: {}
这里使用 docker 的 volumes 来保存 grafana 和 promethues 运行过程中产生的数据来保证持久化,而且使用 GF_SECURITY_ADMIN_PASSWORD=pass 环境变量设置 admin 的密码。
docker-compose 运行之后,grafana 会运行在 http://host-ip:3000 地址,使用浏览器打开会出现登陆页面,输入用户名和刚才配置的密码进入服务。
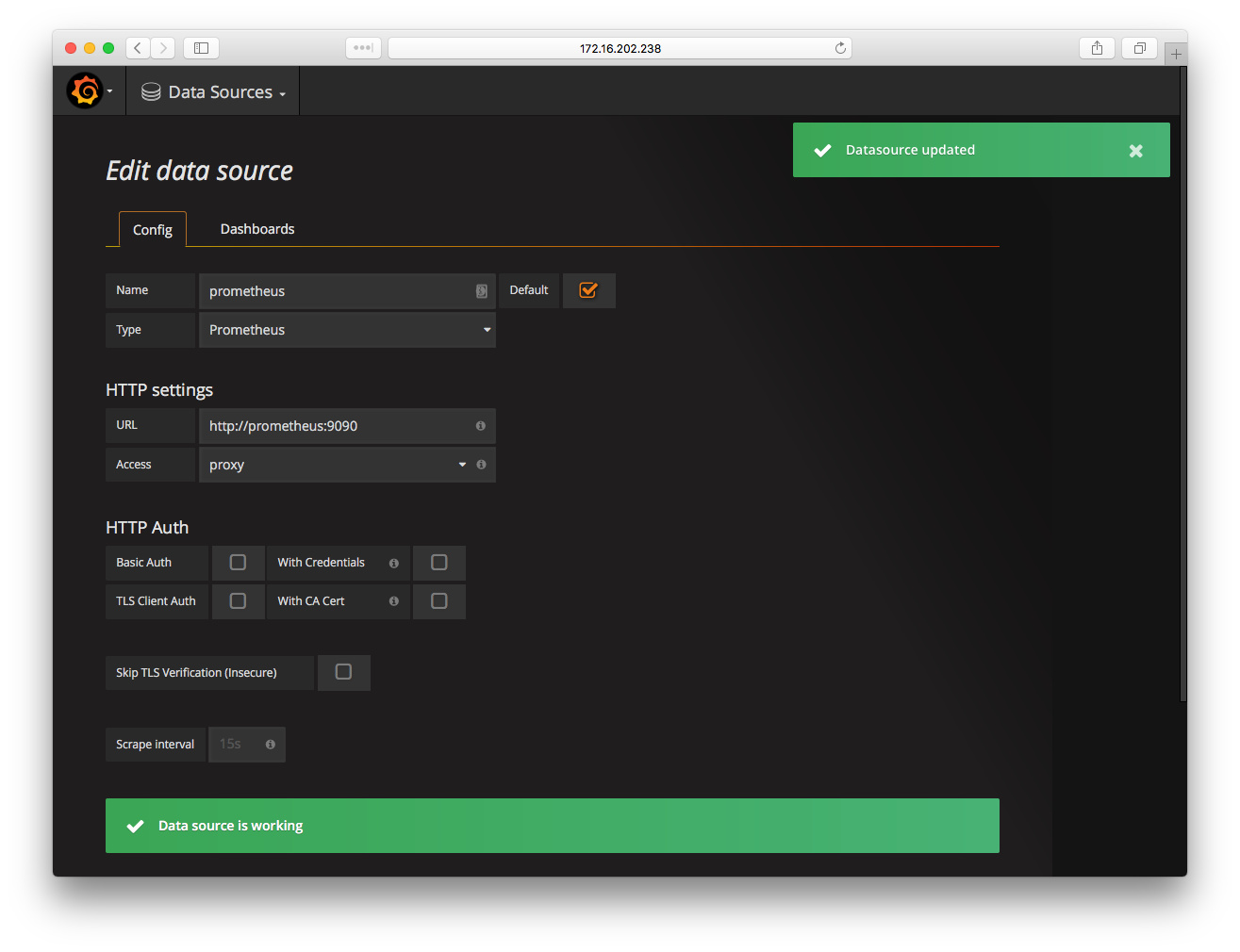
grafana 本身只是一个 dashboard,它可以从多个数据源(时序数据库)中获取数据进行展示,比如我们这里使用的 promethues。所以在正式配置界面之前,需要先添加数据源,点击 grafana 左上角按钮找到 Data Sources 页面或者直接输入 http://host-ip:3000/datasources 地址,会进入对应页面。按照下面的内容进行填写,主要是 Type 要选择 prometheus,URL 添加 grafana 服务能访问的 promethues 地址(因为它们都是通过 docker-compose 运行的,所以这里可以直接使用名字来标识);Name 字段随便填写一个用来标记来源的名字即可。
然后创建一个 dashboard,并里面添加 graph(为了简单,我用了 test dashboard 这个名字),在 graph 中添加一个 panel,我们用这个 panel 展示系统的 load 数据。编辑 panel 数据,选择 data source 为之前添加的 promethues,然后填写 query,系统 node 比较简单,一共是 node_load1、node_load5 和 node_load15,分别是系统最近一分钟、五分钟和十五分钟的 load 数值。输入完成后点击输入框之外,grafana 会自动更新上面的图表:
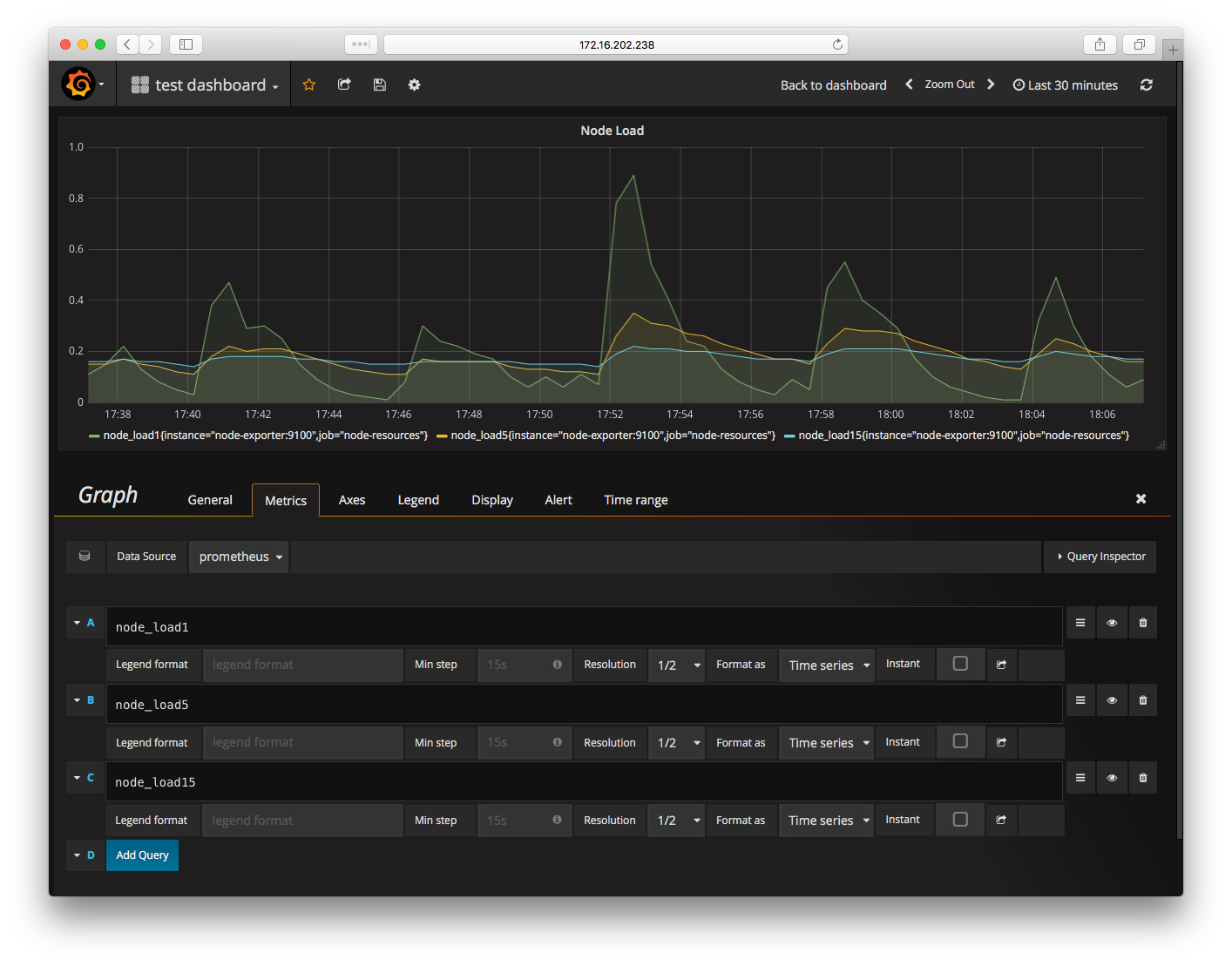
类似的,可以添加其他的 panel,展示系统方方面的监控数据,比如 CPU、memory、IO、网络等。grafana 更多配置可以参考官方文档,选择合适的图表来展示想要的结果。
手动通过界面对 grafana 可以很灵活地创建出很强大的图表,但是这无疑会耗费很多时间(想想,每次搭建 grafana 都要重新做一遍),而且 node exporter 这种监控数据是通用的,如果所有人都手动创建一遍无疑是很多重复工作。为此,grafana 支持导入和导出配置,并且提供官方社区供大家分享 dashboard 配置。
每个 dashboard 都有一个编号,比如编号 22 的 dashboard 就是专门为 node-exporter 设计的展示图表。在 grafana 中点击导入 dashboard,添加编号选择数据源,就能得到已经配置完整的图表:
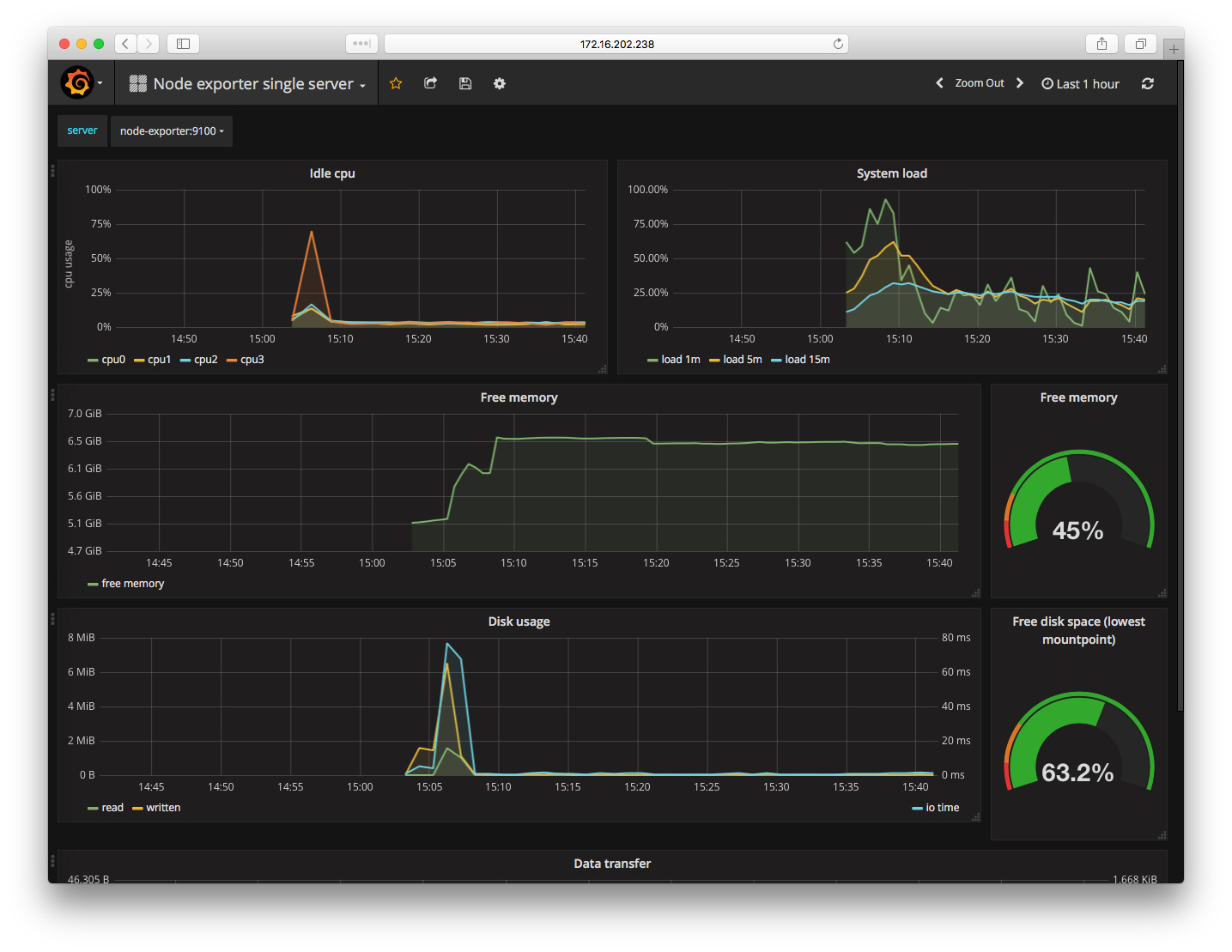
如果对 dashboard 有什么不满,可以直接在页面进行添加和编辑,然后可以导出 json 文件,以便重复使用。
配置告警
通过 grafana 图表我们可以知道系统各种指标随着时间的变化,方便轻松判断系统某个资源是否异常。但是我们不能一直盯着 dashboard,还需要系统发生异常的时候能立即通过邮件或者其他方式通知我们,这就是告警的功能。
promethues 提供用户可以自己配置的告警规则,在处理 metrics 数据的时候,如果发现某个规则被触发,就执行对应的告警动作,通过发邮件或者其他方式通知用户。
对于我们的单节点主机来说,可以定义两个简单的告警规则:当主机 download 掉,或者 CPU load 持续过高一段时间就发送告警。对此,需要新建一个 alert.rules 文件,用来保存告警规则,按照需求对应的内容如下:
➜ monitor git:(master) ✗ cat alert.rules
groups:
- name: node-alert
rules:
- alert: service_down
expr: up == 0
for: 2m
- alert: high_load
expr: node_load1 > 0.5
for: 5m
在启动 promethues 服务的时候把告警规则文件 mount 到 pod 中,如下添加一个 volume:
➜ monitor git:(master) ✗ cat docker-compose.yml
version: '2'
services:
prometheus:
image: prom/prometheus:v2.0.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./alert.rules:/etc/prometheus/alert.rules
......
然后,告知 promethues 加载这些规则:
➜ monitor git:(master) ✗ cat prometheus.yml
......
rule_files:
- 'alert.rules'
为了验证告警规则是否生效,可以把 node-exporter 服务停掉:
docker-compose stop node-exporter
在 promethues 的告警页面(alert) 查看告警:
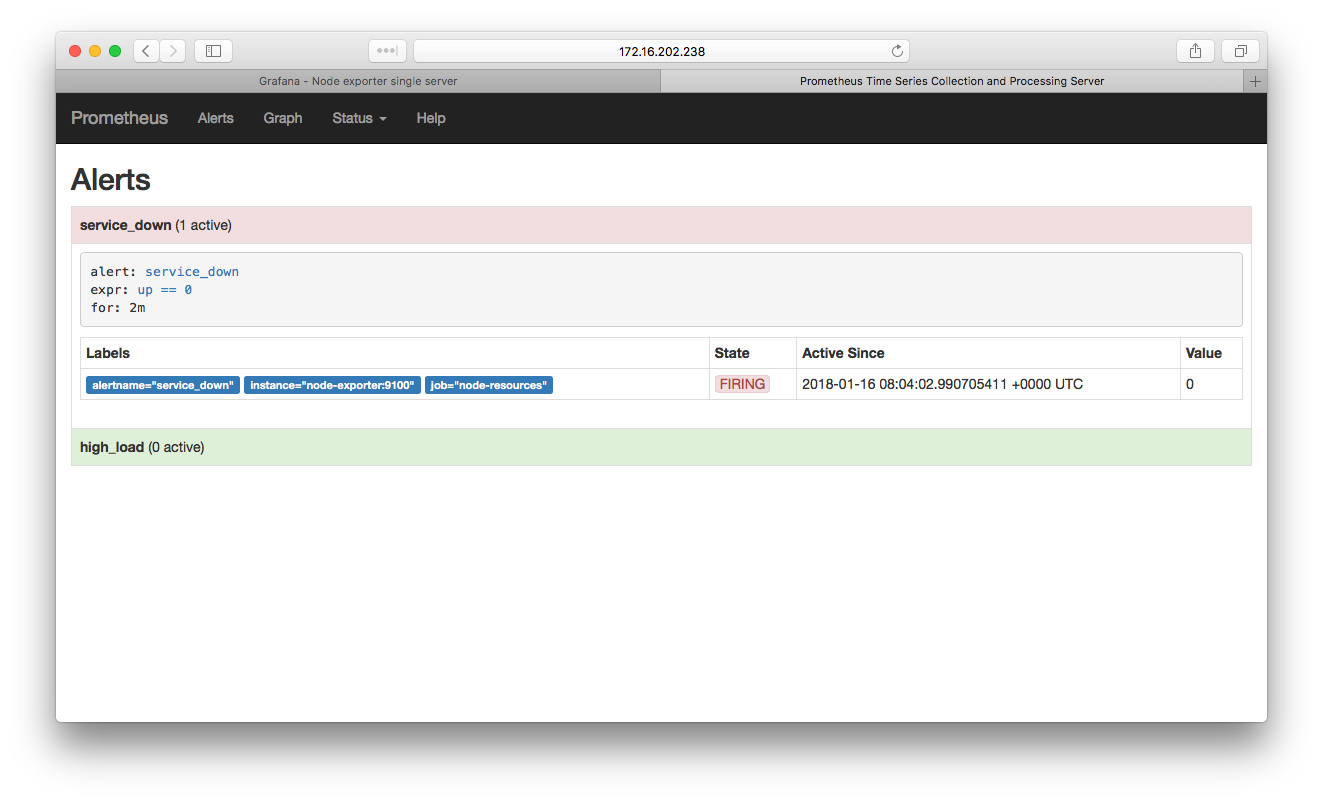
类似地,可以运行一些消耗 CPU 资源的服务来触发系统 load 过高的告警规则,比如运行下面这个 docker 容器(一直 while 循环霸占 CPU 资源可以轻松把 CPU load 提到很高):
docker run --rm -it busybox sh -c "while true; do :; done"
promethues 还提供了 alertmanager 可以自动化根据告警规则触发对应的动作,一般是各种方式通知用户和管理员,这里就不再介绍了。
总结
本文中使用的完整配置文件放到了 github 上,可以作为参考。
需要注意的是,这只是一个本地的 test 环境,不能直接在生产上使用。首先我们没有配置安全访问,所有的服务都是 HTTP;其次 docker-compose 运行的话,所有的服务都是在同一台机器上,无法做到分布式监控和高可用。
如果想在生产中使用 promethues 和 grafana,请参考官方文档。
参考资料
- Installation overview of node_exporter, prometheus and grafana
- Monitoring with Prometheus, Grafana & Docker Part 1
- How To Add a Prometheus Dashboard to Grafana
- Monitoring linux stats with Prometheus.io
- a monitoring solution for docker and containerized services
- How To Query Prometheus on Ubuntu 14.04
