calico 简介
calico 是容器网络的又一种解决方案,和其他虚拟网络最大的不同是,它没有采用 overlay 网络做报文的转发,提供了纯 3 层的网络模型。三层通信模型表示每个容器都通过 IP 直接通信,中间通过路由转发找到对方。在这个过程中,容器所在的节点类似于传统的路由器,提供了路由查找的功能。
要想路由工作能够正常,每个虚拟路由器(容器所在的主机节点)必须有某种方法知道整个集群的路由信息,calico 采用的是 BGP 路由协议,全称是 Border Gateway Protocol。
除了能用于 docker 这样的容器外,它还能集成到容器集群平台 kubernetes、共有云平台 AWS、GCE 等, 而且也能很容易地集成到 openstack 等 Iaas 平台。
这篇文章就介绍 calico 是如何实现 docker 跨主机网络的。
calico 集群安装和实验
这部分我会在自己的 virtualbox 环境中运行多节点 docker,并使用 calico 实现跨主机的容器网络通信功能。实验环境一共启动了三台 centos7 虚拟机:
node00: 172.17.8.100node01: 172.17.8.101node02: 172.17.8.102
这三台机器可以通过上面的 IP 地址进行通信,并且有不同的 hostname,推荐使用 vagrant 运行虚拟机集群。
这部分我们会手动安装 calico 集群,以加深理解,在生产环境中推荐使用自动化安装。
1. 安装 docker
既然要在 docker 集群中测试 calico 网络,当然要有一个能正常工作的 docker 环境。docker 的安装这里就不说了,请参考官网上的安装手册选择适合自己的方式。
2. 安装 etcd
calico 集群的信息需要保存在 etcd 中,因此我们首先要安装 etcd 服务,关于 etcd 的安装可以参考我之前的文章或者 etcd 官方网站。
因为是用来测试,所以我创建了一个单点的 etcd 集群。
3. 配置安装 docker 参数
要想让 docker 支持多节点网络,需要添加 cluster-store 参数,修改 /etc/docker/daemon.json 文件(如果文件不存在需要创建),添加一行内容:
{
"cluster-store": "etcd://172.17.8.100:2379"
}
然后重启 docker 服务,比如 systemctl restart docker,保证 docker 正常运行。
4. 下载 calicoctl 命令行
calico 提供的 calicoctl 命令行工具能简化安装的过程,所以我们需要先下载这个程序:
[~]# wget -O /usr/local/bin/calicoctl https://github.com/projectcalico/calicoctl/releases/download/v1.6.1/calicoctl
[~]# chmod +x /usr/local/bin/calicoctl
上述命令下载的是 1.6.1 版本,如果需要其他版本请按照官方指导下载。
5. 配置 calicoctl 文件
运行的 calico 需要和 etcd 进行交互,因此要事先配置 etcd 的地址以便 calicoctl 使用。calicoctl 有一个配置文件 /etc/calico/calicoctl.cfg,往里面写入如下内容,etcd 地址根据需求更改:
# cat /etc/calico/calicoctl.cfg
apiVersion: v1
kind: calicoApiConfig
metadata:
spec:
datastoreType: "etcdv2"
etcdEndpoints: "http://172.17.8.100:2379"
6. 运行 calico 节点容器
calicoctl 会运行一个 docker 容器来运行 calico,容器镜像默认放在 quay.io/calico/node:latest 上面,在国内需要代理访问,也可以自行创建维护镜像或者事先下载好,这样的话就要把容器镜像指向自己维护的版本:
[root@localhost ~]# calicoctl node run --ip=172.17.8.101 --name node01 --node-image 172.16.1.41:5000/calico/node:v2.6.0
Running command to load modules: modprobe -a xt_set ip6_tables
Enabling IPv4 forwarding
Enabling IPv6 forwarding
Increasing conntrack limit
Removing old calico-node container (if running).
Running the following command to start calico-node:
docker run --net=host --privileged --name=calico-node -d --restart=always -e CALICO_LIBNETWORK_ENABLED=true -e IP=172.17.8.101 -e ETCD_ENDPOINTS=http://172.17.8.100:2379 -e NODENAME=node01 -e CALICO_NETWORKING_BACKEND=bird -v /var/log/calico:/var/log/calico -v /var/run/calico:/var/run/calico -v /lib/modules:/lib/modules -v /run:/run -v /run/docker/plugins:/run/docker/plugins -v /var/run/docker.sock:/var/run/docker.sock 172.16.1.41:5000/calico/node:v2.6.0
Image may take a short time to download if it is not available locally.
Container started, checking progress logs.
Skipping datastore connection test
Using IPv4 address from environment: IP=172.17.8.101
IPv4 address 172.17.8.101 discovered on interface enp0s8
No AS number configured on node resource, using global value
Created default IPv4 pool (192.168.0.0/16) with NAT outgoing true. IPIP mode: off
Created default IPv6 pool (fd80:24e2:f998:72d6::/64) with NAT outgoing false. IPIP mode: off
Using node name: node01
Starting libnetwork service
Calico node started successfully
运行的命令指定了三个参数:
--ip:集群内节点用来互相通信的 IP 地址,如果要多个网卡或者网卡有多个 ip 地址最好手动指定。calicoctl 默认会自动选择这个 IP 地址,要实现自动化可以参考它的 IP 选择配置--name:唯一标识该节点的字符串,如果没有提供会使用 hostname,因此务必要保证 hostname 的唯一性--node-image:calico node 的镜像地址,默认会从quay.io下载最新版本,如果想使用特定版本或者其他地址的镜像,需要手动指定
从命令的输出可以看到,calicoctl 在运行容器之前还做了很多初始化的工作,比如加载需要的模块、配置系统参数、删除已经运行的 calico 容器(如果存在的话);然后还会打印出来要运行的容器命令,所以理论上也可以手动执行这个命令;最后是运行使用的参数说明。
7. 创建网络并测试连通性
在每个节点运行都不部署 calico 容器之后,calico 网络集群就搭建好了。接下来我们会创建两个网络,并测试 calico 跨主机网络的连通性,最终的网络示意图如下:
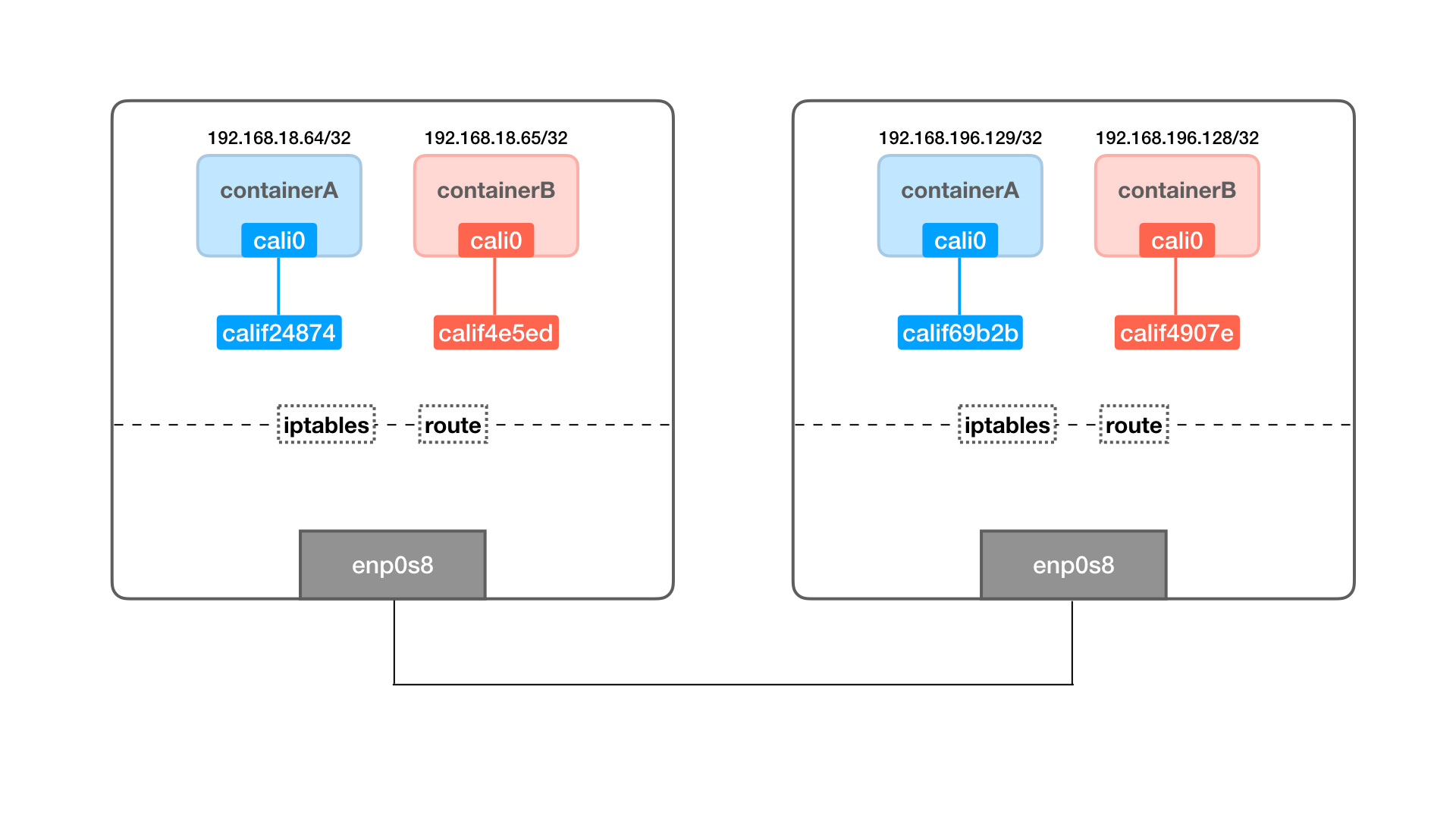
图中只展示了两个节点,每个节点有两个容器,其中蓝色容器在同一个网络,红色容器在另外一个网络。
先创建两个网络:
# docker network create --driver calico --ipam-driver calico-ipam net1
# docker network create --driver calico --ipam-driver calico-ipam net2
docker 创建网络的时候,会调用 calico 的网络驱动,由驱动完成具体的工作。注意这个网络是跨主机的,因此无论在哪台机器创建,在其他机器上都能看到:
[root@node01 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
ea7007efb6d1 bridge bridge local
f76e9fe0eacc host host local
c9bc43f8c601 net1 calico global
ecda22cb8142 net2 calico global
然后分别在网络中运行容器:
node00:
# docker run --net net1 --name containerA -tid busybox
# docker run --net net2 --name containerB -tid busybox
node01:
# docker run --net net1 --name containerC -tid busybox
# docker run --net net2 --name containerD -tid busybox
可以测试 containerA 和 containerC 能互相通信,containerB 和 containerD 能互相通信:
[root@node00 ~]# docker exec -it containerA ping -c 3 containerC
PING containerC (192.168.196.129): 56 data bytes
64 bytes from 192.168.196.129: seq=0 ttl=62 time=50.587 ms
64 bytes from 192.168.196.129: seq=1 ttl=62 time=50.921 ms
64 bytes from 192.168.196.129: seq=2 ttl=62 time=51.688 ms
--- containerC ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 50.587/51.065/51.688 ms
同一个网络 docker 会保存各自的名字和 IP 的对应关系,而不同网络的容器无法解析,而且不能相互通信:
[root@node00 ~]# docker exec -it containerA ping -c 3 192.168.196.128
PING 192.168.196.128 (192.168.196.128): 56 data bytes
--- 192.168.196.128 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
报文流程
我们来分析同个网络不同节点的容器是怎么通信的,借此还原 calico 的实现原理。以 containerA ping containerC 为例,先进入 containerA 中查看它的网络配置和路由表:
[root@node00 ~]# docker exec -it containerA sh
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
5: cali0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff
inet 192.168.18.64/32 scope global cali0
valid_lft forever preferred_lft forever
可以看到 containerA 的 ip 地址为 192.168.18.64/32,需要注意的是它的 MAC 地址为 ee:ee:ee:ee:ee:ee,很明显是个固定的特殊地址(事实上所有 calico 生成的容器 MAC 地址都一样),这么做的是因为 calico 只关心三层的 IP 地址,根本不关心二层 MAC 地址。为什么这么说?等我们分析完,你就知道了。
要 ping 的目的地址为 192.168.196.129/32,两者不再同一个网络中,所以会查看路由获取下一跳的地址:
/ # ip route
default via 169.254.1.1 dev cali0
169.254.1.1 dev cali0
容器的路由表非常有趣,和一般服务器创建的规则不同,所有的报文都会经过 cali0 发送到下一跳 169.254.1.1(这是预留的本地 IP 网段),这是 calico 为了简化网络配置做的选择,容器里的路由规则都是一样的,不需要动态更新。知道下一跳之后,容器会查询下一跳 168.254.1.1 的 MAC 地址,这个 ARP 请求发到哪里了呢?要回答这个问题,就要知道 cali0 是 veth pair 的一端,其对端是主机上 caliXXXX 命名的 interface,可以通过 ethtool -S cali0 列出对端的 interface idnex。
# ethtool -S cali0
NIC statistics:
peer_ifindex: 6
而主机上 index 为 6 的 interface 为:
# ip addr
6: calif24874aae57: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether a2:ff:0a:99:57:d2 brd ff:ff:ff:ff:ff:ff
inet6 fe80::a0ff:aff:fe99:57d2/64 scope link
valid_lft forever preferred_lft forever
报文会发送到这个 interface,这个 interface 有一个随机分配的 MAC 地址,但是没有
IP地址,接收到想要 169.254.1.1 MAC 地址的 ARP 请求报文,它会怎么做呢?这个又不是它的 IP,而且它又没有和任何的 bridge 相连可以广播 ARP 报文。
只能抓包看看了,记住要先删除容器中 169.254.1.1 对应的 ARP 表项(使用 ip neigh del 命令),然后运行 ping 的时候在主机上抓包:
[root@node00 ~]# tcpdump -nn -i calif24874aae57 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on calif24874aae57, link-type EN10MB (Ethernet), capture size 262144 bytes
13:54:28.280252 ee:ee:ee:ee:ee:ee > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 169.254.1.1 tell 192.168.18.64, length 28
13:54:28.280274 a2:ff:0a:99:57:d2 > ee:ee:ee:ee:ee:ee, ethertype ARP (0x0806), length 42: Reply 169.254.1.1 is-at a2:ff:0a:99:57:d2, length 28
13:54:28.280280 ee:ee:ee:ee:ee:ee > a2:ff:0a:99:57:d2, ethertype IPv4 (0x0800), length 98: 192.168.18.64 > 192.168.196.129: ICMP echo request, id 25581, seq 1, length 64
13:54:28.280669 a2:ff:0a:99:57:d2 > ee:ee:ee:ee:ee:ee, ethertype IPv4 (0x0800), length 98: 192.168.196.129 > 192.168.18.64: ICMP echo reply, id 25581, seq 1, length 64
从前面两个报文可以看到,接收到 ARP 请求后,它直接进行了应答,应答报文中 MAC 地址是 a2:ff:0a:99:57:d2,这正是该 interface 自己的 MAC 地址。换句话说,它把自己的 MAC 地址作为应答返回给容器。容器的后续报文 IP 地址还是目的容器,但是 MAC 地址就变成了主机上该 interface 的地址,也就是说所有的报文都会发给主机,然后主机根据 IP 地址进行转发。
主机这个 interface 不管 ARP 请求的内容,直接用自己的 MAC 地址作为应答的行为被成为 ARP proxy,是 calico 开启的,可以通过下面的命令确认:
# cat /proc/sys/net/ipv4/conf/calif24874aae57/proxy_arp
1
总的来说,可以认为 calico 把主机作为容器的默认网关来使用,所有的报文发到主机,然后主机根据路由表进行转发。和经典的网络架构不同的是,calico 并没有给默认网络配置一个 IP 地址(这样每个网络都会额外消耗一个 IP 资源,而且主机上也会增加对应的 IP 地址和路由信息),而是通过 arp proxy 和修改容器路由表来实现。
主机的 interface 接收到报文之后,下面的事情就容易理解了,所有的报文会根据路由表来走:
[root@node00 ~]# ip route
169.254.0.0/16 dev enp0s3 scope link metric 1002
169.254.0.0/16 dev enp0s8 scope link metric 1003
192.168.18.64 dev calif24874aae57 scope link
blackhole 192.168.18.64/26 proto bird
192.168.18.65 dev cali4e5ed993aed scope link
192.168.196.128/26 via 172.17.8.101 dev enp0s8 proto bird
而我们的 ping 报文目的地址是 192.168.196.129,匹配的是最后一个表项,把 172.17.8.101 作为下一跳地址,并通过 enp0s8 发出去。这个路由规则匹配的是一个网段,也就是说该网段所有的容器 IP 都在目的主机上,可以推测 calico 为每个主机默认分配了一段子网。
NOTE:在发送到另一台主机之前,报文还会经过 iptables,calico 设置的 ACL 规则还会过滤报文。这个步骤暂时先跳过,我们先认为报文能够被继续转发。
报文到达容器所在的主机 172.17.8.101,下一步怎么走呢?当然是看路由器(这里还是跳过 iptables 的检查步骤):
[root@node01 ~]# ip route
169.254.0.0/16 dev enp0s3 scope link metric 1002
169.254.0.0/16 dev enp0s8 scope link metric 1003
192.168.18.64/26 via 172.17.8.100 dev enp0s8 proto bird
192.168.196.128 dev cali4907e793262 scope link
blackhole 192.168.196.128/26 proto bird
192.168.196.129 dev cali69b2b8c106c scope link
同样的,这个报文会匹配最后一个路由规则,这个规则匹配的是一个 IP 地址,而不是网段,也就是说主机上每个容器都会有一个对应的路由表项。报文发送到 cali69b2b8c106c 这个 veth pair,然后从另一端发送给容器,容器接收到报文之后,发送目的地址是自己,就做出 ping 应答,应答报文的返回路径和之前类似。
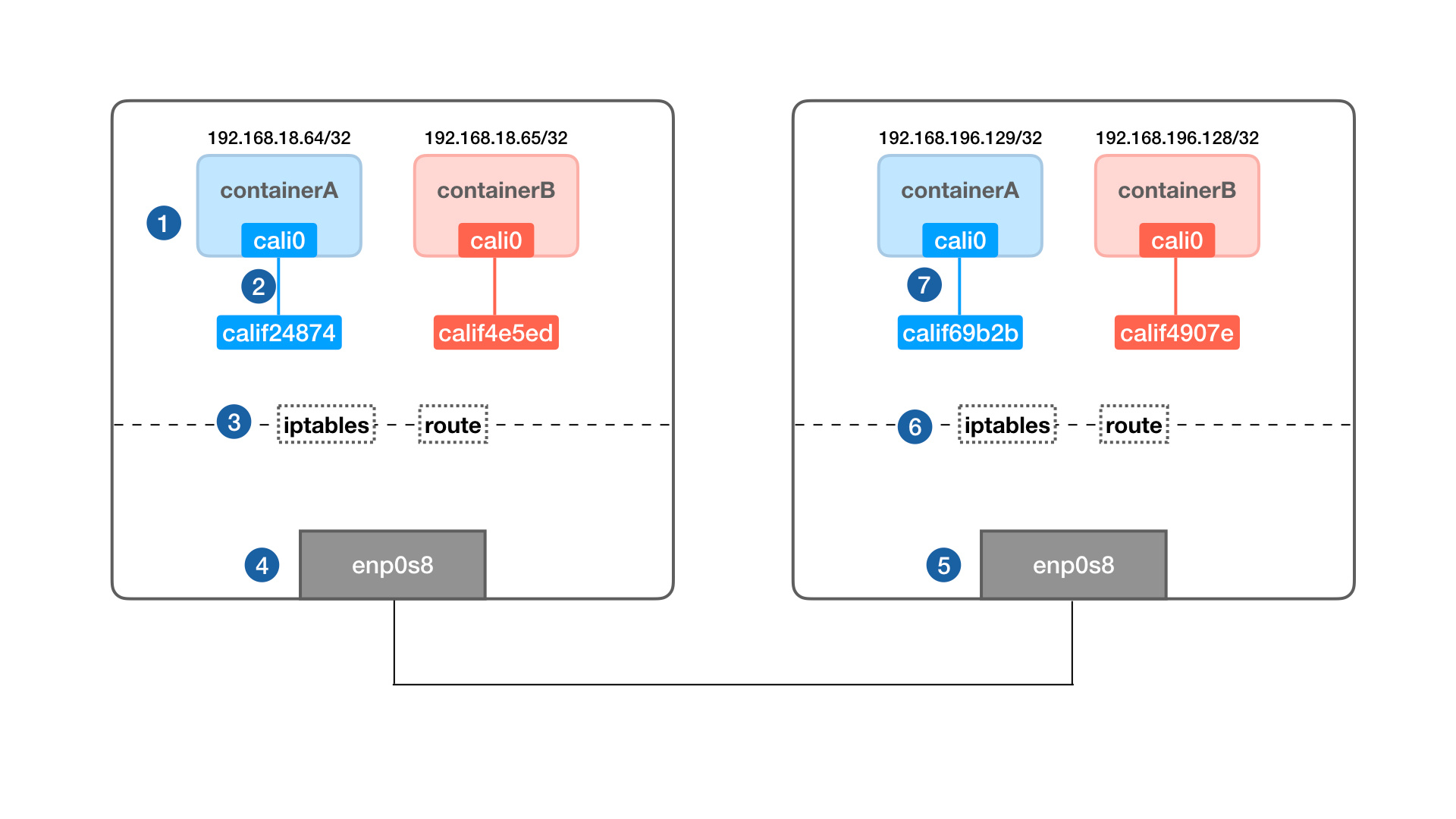
总体的报文路径就是按照下图中的数字顺序,回来的报文按照原路返回:
组件和架构
看完 calico 的报文流程,大致也能分析出 calico 做的事情:
- 分配和管理 IP
- 配置上容器的 veth pair 和容器内默认路由
- 根据集群网络情况实时更新节点上路由表
从部署过程可以知道,除了 etcd 保存了数据之外,节点上也就只运行了一个 calico-node 的容器,所以推测是这个容器实现了上面所有的功能。calico/node 这个容器运行了多个组件:
[root@node00 ~]# docker exec -it calico-node sh
/ # ps aux
PID USER TIME COMMAND
1 root 0:01 /sbin/runsvdir -P /etc/service/enabled
75 root 0:00 runsv felix
76 root 0:00 runsv bird
77 root 0:00 runsv bird6
78 root 0:00 runsv confd
79 root 0:00 runsv libnetwork
80 root 0:02 svlogd /var/log/calico/felix
81 root 30:49 calico-felix
82 root 0:00 svlogd /var/log/calico/confd
83 root 0:05 confd -confdir=/etc/calico/confd -interval=5 -watch --log-level=debug -node=http://172.17.8.100:2379 -client-key= -client-cert= -client-ca-keys=
84 root 0:00 svlogd -tt /var/log/calico/bird
85 root 0:20 bird -R -s /var/run/calico/bird.ctl -d -c /etc/calico/confd/config/bird.cfg
86 root 0:00 svlogd -tt /var/log/calico/bird6
87 root 0:18 bird6 -R -s /var/run/calico/bird6.ctl -d -c /etc/calico/confd/config/bird6.cfg
94 root 0:00 svlogd /var/log/calico/libnetwork
95 root 0:04 libnetwork-plugin
runsv 是一个 minimal 的 init 系统提供的命令,用来管理多个进程,可以看到它运行的进程包括:felix、bird、bird6、confd 和 libnetwork,这部分就介绍各个进程的功能。
libnetwork plugin
libnetwork-plugin 是 calico 提供的 docker 网络插件,主要提供的是 IP 管理和网络管理的功能。
默认情况下,当网络中出现第一个容器时,calico 会为容器所在的节点分配一段子网(子网掩码为 /26,比如192.168.196.128/26),后续出现在该节点上的容器都从这个子网中分配 IP 地址。这样做的好处是能够缩减节点上的路由表的规模,按照这种方式节点上 2^6 = 64 个 IP 地址只需要一个路由表项就行,而不是为每个 IP 单独创建一个路由表项。节点上创建的子网段可以在etcd 中 /calico/ipam/v2/host/<node_name>/ipv4/block/ 看到。
calico 还允许创建容器的时候指定 IP 地址,如果用户指定的 IP 地址不在节点分配的子网段中,calico 会专门为该地址添加一个 /32 的网段。
BIRD
BIRD(BIRD Internet Routing Daemon) 是一个常用的网络路由软件,支持很多路由协议(BGP、RIP、OSPF等),calico 用它在节点之间共享路由信息。
关于 BIRD 如何配置 BGP 协议,可以参考官方文档,对应的配置文件在 /etc/calico/confd/config/ 目录。
NOTE:至于为什么选择 BGP 协议而不是其他的路由协议,官网上也有介绍: Why BGP?
默认所有的节点使用相同的 AS number 64512,因为 AS number 是一个32 比特的字段,所以有效取值范围是 [0-4294967295],可以通过 calicoctl config get asNumber 命令查看当前节点使用的 AS number。
默认情况下,每个 calico 节点会和集群中其他所有节点建立 BGP peer 连接,也就是说这是一个 O(n^2) 的增长趋势。在集群规模比较小的情况下,这种模式是可以接受的,但是当集群规模扩展到百个节点、甚至更多的时候,这样的连接数无疑会带来很大的负担。为了解决集群规模较大情况下 BGP client 连接数膨胀的问题,calico 引入了 RR(Router Reflector) 的功能。
RR 的基本思想是选择一部分节点(一个或者多个)作为 Global BGP Peer,它们和所有的其他节点互联来交换路由信息,其他的节点只需要和 Global BGP Peer 相连就行,不需要之间再两两连接。更多的组网模式也是支持的,不管怎么组网,最核心的思想就是所有的节点能获取到整个集群的路由信息。
calico 对 BGP 的使用还是相对简单的,BGP 协议的原理不是一两句话能解释清楚的,以后有机会单独写篇文章来说吧。
confd
因为 bird 的配置文件会根据用户设置的变化而变化,因此需要一种动态的机制来实时维护配置文件并通知 bird 使用最新的配置,这就是 confd 的工作。confd 监听 etcd 的数据,用来更新 bird 的配置文件,并重新启动 bird 进程让它加载最新的配置文件。confd 的工作目录是 /etc/calico/confd,里面有三个目录:
conf.d:confd需要读取的配置文件,每个配置文件告诉 confd 模板文件在什么,最终生成的文件应该放在什么地方,更新时要执行哪些操作等config:生成的配置文件最终放的目录templates:模板文件,里面包括了很多变量占位符,最终会替换成 etcd 中具体的数据
具体的配置文件很多,我们只看一个例子:
/ # cat /etc/calico/confd/conf.d/bird.toml
[template]
src = "bird.cfg.mesh.template"
dest = "/etc/calico/confd/config/bird.cfg"
prefix = "/calico/bgp/v1"
keys = [
"/host",
"/global"
]
check_cmd = "bird -p -c {{.src}}"
reload_cmd = "pkill -HUP bird || true"
它会监听 etcd 的 /calico/bgp/v1 路径,一旦发现更新,就用其中的内容更新模板文件 bird.cfg.mesh.template,把新生成的文件放在 /etc/calico/confd/config/bird.cfg,文件改变之后还会运行 reload_cmd 指定的命令重启 bird 程序。
NOTE:关于 confd 的使用和工作原理请参考它的官方 repo。
felix
felix 负责最终网络相关的配置,也就是容器网络在 linux 上的配置工作,比如:
- 更新节点上的路由表项
- 更新节点上的 iptables 表项
它的主要工作是从 etcd 中读取网络的配置,然后根据配置更新节点的路由和 iptables,felix 的代码在 github projectcalico/felix。
etcd
etcd 已经在前面多次提到过,它是一个分布式的键值存储数据库,保存了 calico 网络元数据,用来协调 calico 网络多个节点。可以使用 etcdctl 命令行来读取 calico 在 etcd 中保存的数据:
# etcdctl -C 172.17.8.100:2379 ls /calico
/calico/ipam
/calico/v1
/calico/bgp
每个目录保存的数据大致功能如下:
/calico/ipam:IP 地址分配管理,保存了节点上分配的各个子网段以及网段中 IP 地址的分配情况/calico/v1:profile 和 policy 的配置信息,节点上运行的容器 endpoint 信息(IP 地址、veth pair interface 的名字等),/calico/bgp:和 BGP 相关的信息,包括 mesh 是否开启,每个节点作为 gateway 通信的 IP 地址,AS number 等
强大的防火墙功能
从前面的实验我们不仅知道了 calico 容器网络的报文流程是怎样的,还发现了一个事实:默认情况下,同一个网络的容器能通信(不管容器是不是在同一个主机上),不同网络的容器是无法通信的。
这个行为是 calico 强大的防火墙实现的,默认情况下 calico 为每个网络创建一个 profile:
[root@node01 ~]# calicoctl get profile net2 -o yaml
- apiVersion: v1
kind: profile
metadata:
name: net2
tags:
- net2
spec:
egress:
- action: allow
destination: {}
source: {}
ingress:
- action: allow
destination: {}
source:
tag: net2
- profile 是和网络对应的,比如上面
metadata.name的值是net2,代表它匹配net2网络,并应用到所有的net2网络容器中 - calico 使用 label 来增加防火墙规则的灵活性,源地址和目的地址都可以通过 label 匹配
- profile 中
metadata.tags会应用到网络中所有的容器上 - 如果有定义,profile中的
metadata.labels也会应用到网络中所有的容器上 - spec 指定 profile 默认的网络规则,egress 没有限制,ingress 表示只运行 tag 为 net2 容器(也就是同一个网络的容器)的访问
每一个加入到网络的容器都会加上这个 profile,以此来实现网络之间的隔离。可以通过查看 endpoints 的详情得到它上面绑定的 profiles:
[root@node01 ~]# calicoctl get workloadEndpoint 4e5ed993aed9e7c89bd5514fa67a2a8346295238801974d77eac8b444ae2afb0 -o yaml
- apiVersion: v1
kind: workloadEndpoint
metadata:
name: 4e5ed993aed9e7c89bd5514fa67a2a8346295238801974d77eac8b444ae2afb0
node: node00
orchestrator: libnetwork
workload: libnetwork
spec:
interfaceName: cali4e5ed993aed
ipNetworks:
- 192.168.18.65/32
mac: ee:ee:ee:ee:ee:ee
profiles:
- net2
用户也可以根据需求修改 profile 和 policy,可以参考官方教程。
不过上面的防火墙都是针对网络的(网络中的容器的规则都是相同的),不能精细化到容器,也就是说只能做到网络之间的隔离和连通。不过 calico 也提供了对容器级别防火墙的支持,它主要是借助 docker 容器上的 label,通过匹配这些键值对来精细化控制防火墙。启动 docker label 支持需要在 calicoctl node run 命令运行时加上 --use-docker-networking-container-labels 参数,而且一旦启用后原来的 profile 就被废弃不能用了(可以用纯 policy 实现原来的 profile 功能)。容器启动的时候需要添加上 label 用来作为 policy 的标识,比如 --label org.projectcalico.label.role=frontend,具体的使用案例请参考这个教程。
如果只要提供网络之间的隔离,可以使用 profile 和 policy;如果要实现精细化的容器之间的隔离,就需要启用容器的 label 功能了。在底层,calico 的 flelix 组件会实时跟踪 profile 和 policy 的内容,并更新各个节点的 iptables。
总结
calico 的核心是通过维护路由规则实现容器的通信,路由信息的传播是 BIRD 软件通过 BGP 协议完成的,而节点上路由和防火墙规则是 felix 维护的。
从 calico 本身的特性来说,它没有办法实现 VPC 网络,并且需要维护大量的路由表项和 iptables 表项,如果要部署在规模很大的生产环境中,需要预先规划系统的 iptables 和路由表项的上限。
在我看来,calico 最大的优点有两个:直接三层互联的网络,不需要报文封装,因此性能更好而且能和原来的网络设施直接融合;强大的防火墙规则,利用 label 机制灵活地匹配容器,几乎可以设置任何需求的防火墙。
但 calico 并非没有缺点,首先是它引入了 BGP 协议,虽然 bird 的配置很简单,但是运维这个系统需要熟悉 BGP 协议,这无疑会增加了人力、时间和金钱方面的投入;其次,calico 能支持的网络规模也有上限,虽然可以通过 Router Reflector 来缓解,但这么做又大大增加了网络规划、使用和排查的复杂度;最后 calico 无法用来实现 VPC 网络,IP 地址空间是所有租户共享的,租户之间是通过防火墙隔离的。
