在开始之前,先定义一些基本的概念。
- 明文P(Plain text):指没有经过加密的普通文本
- 密文C(Cipher text):指加密后的文本
- 加密(Encryption/Encipherment):将明文转化为密文的过程
- 解密(Decryption/Decipherment):将密文还原为明文的过程
- 加密钥匙Ek(Encryption Key):加密时使用的钥匙(配合加密算法的数据)
- 解密钥匙Dk(Decryption Key):解密时使用的钥匙(配合解密算法的数据)
有几点需要实现声明的:
- 下面的加密方式都是针对英文的
- 所有的编码方式都是 ASCII 码
- 加密和解密只关注字母,不关注标点,空格等特殊字符
凯撒密码
凯撒密码比较简单,非常容易理解。它属于替换式密码,基本概念就是把明文的字母在字母表上向后(或向前)按照一个固定数目进行偏移后变成密文。下面是维基百科给出的示意图:

根据偏移量的不同,还存在若干特定的恺撒密码名称:
- 偏移量为10:Avocat(A→K)
- 偏移量为13:ROT13
- 偏移量为-5:Cassis (K 6)
- 偏移量为-6:Cassette (K 7)
用数学的方式来表达整个过程的话,需要把字母转换为对应的数字,A = 0, B = 1, …, Z = 25,可以用
x 来表示,密钥就是偏移量 K。加密算法和解密算法分别是:
加密: $$E_k(x) = (x + k) mod 26$$
解密: $$E_k(x) = (x - k) mod 26$$
加密和解密
破解
要破解凯撒密码加密的文本,可以分两种情况讨论:
已经知道密文是凯撒密码加密的,只是不知道密钥
可以使用暴力法,因为密钥一共只有 25 种可能,遍历所有的可能结果,使用人工识别的方法找到有意义的一组,就能知道密钥。当然也可以使用字典法自动识别破解结果,这就要求原文是按照空格分开的,否则还需要单词分解。知道(猜测)密文是某种替换密码加密的
可以使用字母频率分析的方法来破解密码,最直观的方法解释计算所有字母的频率,得到最高的字母 x,那么它对应的明文字母就是 e,两者之间的差距就是密钥 k。但是这种方法有一个致命的缺点,需要的文本要足够长,才能满足概率分布的随机性。比如要破解下面一句话加密的密文就不太可能:Do not go gentle into that good night
因为,
o和t出现的次数最多(六次),g出现了四次,而e只出现了一次。可以看出来上面的破解方法的缺点:只考虑了一个字母的分布。为了得到更准确的算法,我们必须全盘考虑。假设统计的字母分布为:
$$W = {w_a, w_b, .. , w_z}$$而要破解的文本字母分布为:
$$G = {g_a, g_b, .. , g_z}$$
只有当下面的结果最小时,我们才能说找到了密钥 k:
$$\sum_{i=a}^z(w_i - g_i^k)^2$$
$$g_i^k 表示在偏移 k 时字母 i 的概率$$
from operation import add,sub
from funtools import partial
def _tran_letter(letter, oper=add, step=10):
if letter.isalpha():
base = ord('A') if letter.isupper() else ord('a')
return chr(oper((ord(letter) - base), step) % 26 + base)
return letter
def decrypt(cipher, step):
decrypt_letter = partial(_tran_letter, oper=sub, step=step)
return ''.join(map(decrypt_letter, ciphercipher)).strip()
def crack(cipher):
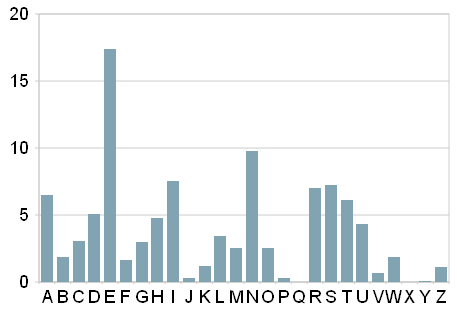
weight = [6.51, 1.89, 3.06, 5.08, 17.4,
1.66, 3.01, 4.76, 7.55, 0.27,
1.21, 3.44, 2.53, 9.78, 2.51,
0.29, 0.02, 7.00, 7.27, 6.15,
4.35, 0.67, 1.89, 0.03, 0.04, 1.13]
freq = [0] * 26
guess = [0] * 26
# first calculate frequencies of letter in strings
for character in cipher:
if character.isalpha():
freq[ord(character.lower()) - ord('a')] += 1
# now for every possible offset k, calculate each letter
# frequecncies and find out the most fit one.
for offset in range(26):
for letter in range(26):
guess[offset] += 0.1 * weight[letter] * \
freq[(letter + offset) % 26]
key = guess.index(max(guess))
return self.decrypt(cipher, key)
维吉尼亚密码

维吉尼亚密码是凯撒密码的加强版,下表是凯撒密码的对照表。第 k 行是密钥为 k 时,字母表加密后的各字母。
加密和解密
维吉尼亚密码不使用固定的密钥 k,而是使用变化的一系列密钥 $$$k_1,k_2,k_3,…,k_n$$$。前面已经说过,字母和 [0-25] 之间可以互相转换,所以可以使用一个单词作为密钥。如果密钥的长度不够,则重新从头开始,相当于密钥会自动扩展成 $$$k_1,k_2,k_3,…,k_n,k_1,k_2,…$$$。假如我们的密钥是 interstellar,要加密的文本是 Do not go gentle into that good night,加密后的密文就是 Lb gsk yh kpyxcm vgxf laee rsfl abkyl。
| key | plain | cipher |
|---|---|---|
| i | D | L |
| n | o | b |
| t | n | g |
| e | o | s |
| r | t | k |
| … | … | … |
| n | n | a |
| t | i | b |
| e | g | k |
| r | h | y |
| s | t | l |
解密的过程相反,根据密文和密钥找到对应的字母就可以了。
破解
维吉尼亚密码使用暴力破解的复杂度很高,如果密文的长度是 L,则一共有 $$$26^L$$$ 种可能。那么频率分析的方法呢?因为相同的明文也会得到不同的密文,所以密文字母的概率分布和英文字母的分布差异会很大。
不难看出破解的难度在于我们不知道密钥的长度和内容,如果密文长度是 L, 则密钥的长度有可能是 [1, L] 区间的任意一个。如果我们知道了密钥的长度 k,问题就变得简单:把密文按照步长可以分成 k 组,每组的字母是位置相差 k 的所有字母,也就是说它们的加密使用的是同个字母。那么每组都是凯撒密码加密的密文,分别用凯撒密码的解密算法就能得到明文。
那么,怎么算出密钥的长度 k 呢?可以对 k 的长度从 1 到 L 遍历,找到最接近最值的 k,就是想要的结果。
怎么定义这个最值呢?我们要引出另外的一个概念:重合指数(index of coincidence)。
重合指数是两个随机选出的字母相同的的概率,即随机选出两个 A 的概率 + 随机选出两个 B 的概率+随机选出两个 C 的概率 + …… + 随机选出两个 Z 的概率。根据统计的概率分布表,可以算出这个值:
$$ \sum_{i=A}^ZP(i)^2 = P(A)^2 + P(B)^2 + … + P(Z)^2 = 0.65$$
利用重合指数推测密钥长度的原理在于,对于一个由凯撒密码加密的序列,由于所有字母的位移程度相同,所以密文的重合指数应等于原文语言的重合指数。这也是所有重合指数的最大值(不会在次证明,有兴趣可以自行证明)。
